
Part 1: Building an Architecture to Support Domain Modeling
Most developers have never seen a domain model, only a data model.
DDD EU 2017
Most developers we talk to about architecture have a nagging sense that things could be better. They are often trying to rescue a system that has gone wrong somehow, and are trying to put some structure back into a ball of mud. They know that their business logic shouldn’t be spread all over the place, but they have no idea how to fix it.
We’ve found that many developers, when asked to design a new system, will immediately start to build a database schema, with the object model treated as an afterthought. This is where it all starts to go wrong. Instead, behavior should come first and drive our storage requirements. After all, our customers don’t care about the data model. They care about what the system does; otherwise they’d just use a spreadsheet.
The first part of the book looks at how to build a rich object model through TDD (in [chapter_01_domain_model]), and then we’ll show how to keep that model decoupled from technical concerns. We show how to build persistence-ignorant code and how to create stable APIs around our domain so that we can refactor aggressively.
To do that, we present four key design patterns:
-
The Repository pattern, an abstraction over the idea of persistent storage
-
The Service Layer pattern to clearly define where our use cases begin and end
-
The Unit of Work pattern to provide atomic operations
-
The Aggregate pattern to enforce the integrity of our data
If you’d like a picture of where we’re going, take a look at A component diagram for our app at the end of [part1], but don’t worry if none of it makes sense yet! We introduce each box in the figure, one by one, throughout this part of the book.
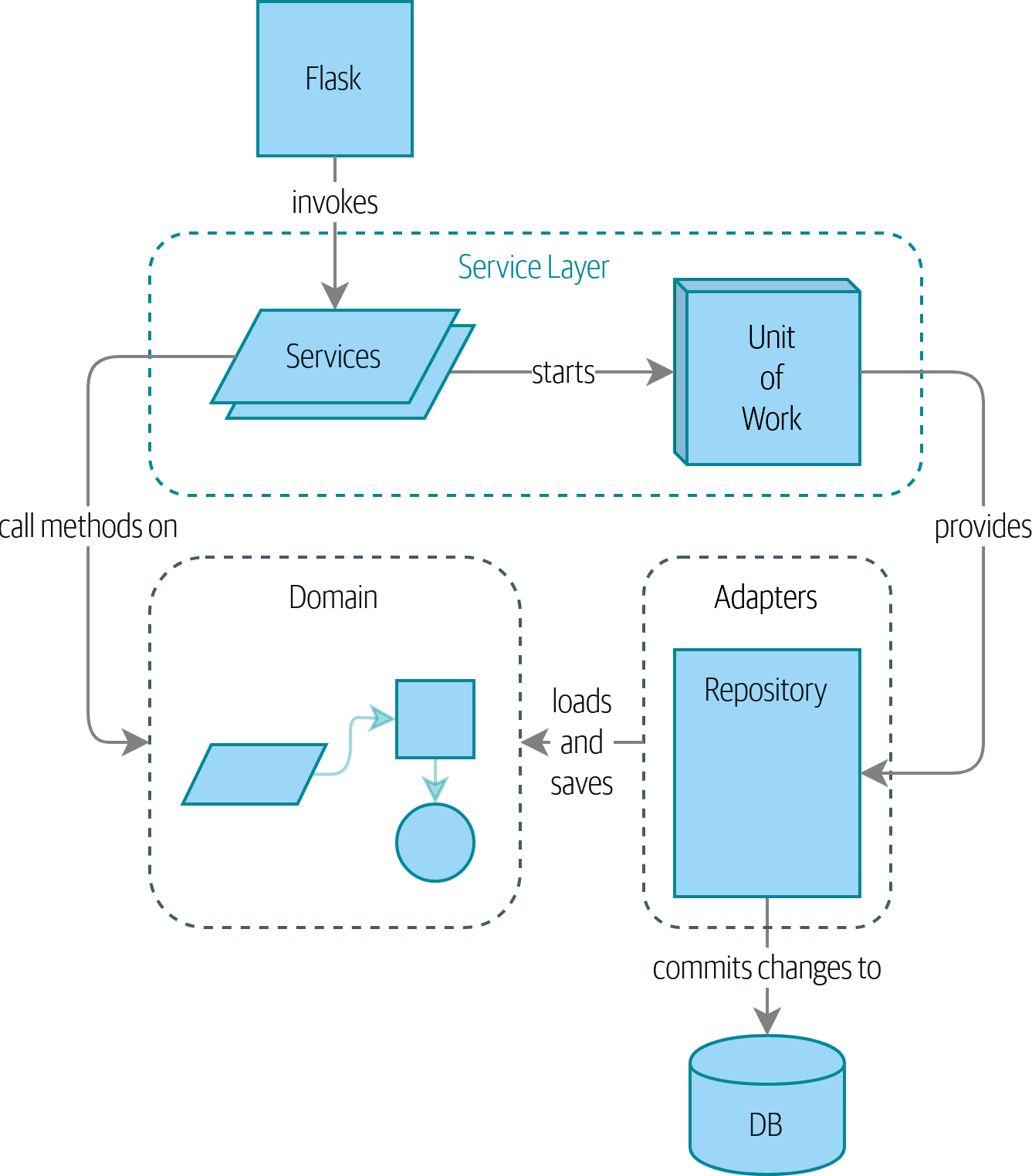
We also take a little time out to talk about coupling and abstractions, illustrating it with a simple example that shows how and why we choose our abstractions.
Three appendices are further explorations of the content from Part I:
-
[appendix_project_structure] is a write-up of the infrastructure for our example code: how we build and run the Docker images, where we manage configuration info, and how we run different types of tests.
-
[appendix_csvs] is a "proof of the pudding" kind of content, showing how easy it is to swap out our entire infrastructure—the Flask API, the ORM, and Postgres—for a totally different I/O model involving a CLI and CSVs.
-
Finally, [appendix_django] may be of interest if you’re wondering how these patterns might look if using Django instead of Flask and SQLAlchemy.