
12: Command-Query Responsibility Segregation (CQRS)
In this chapter, we’re going to start with a fairly uncontroversial insight: reads (queries) and writes (commands) are different, so they should be treated differently (or have their responsibilities segregated, if you will). Then we’re going to push that insight as far as we can.
If you’re anything like Harry, this will all seem extreme at first, but hopefully we can make the argument that it’s not totally unreasonable.
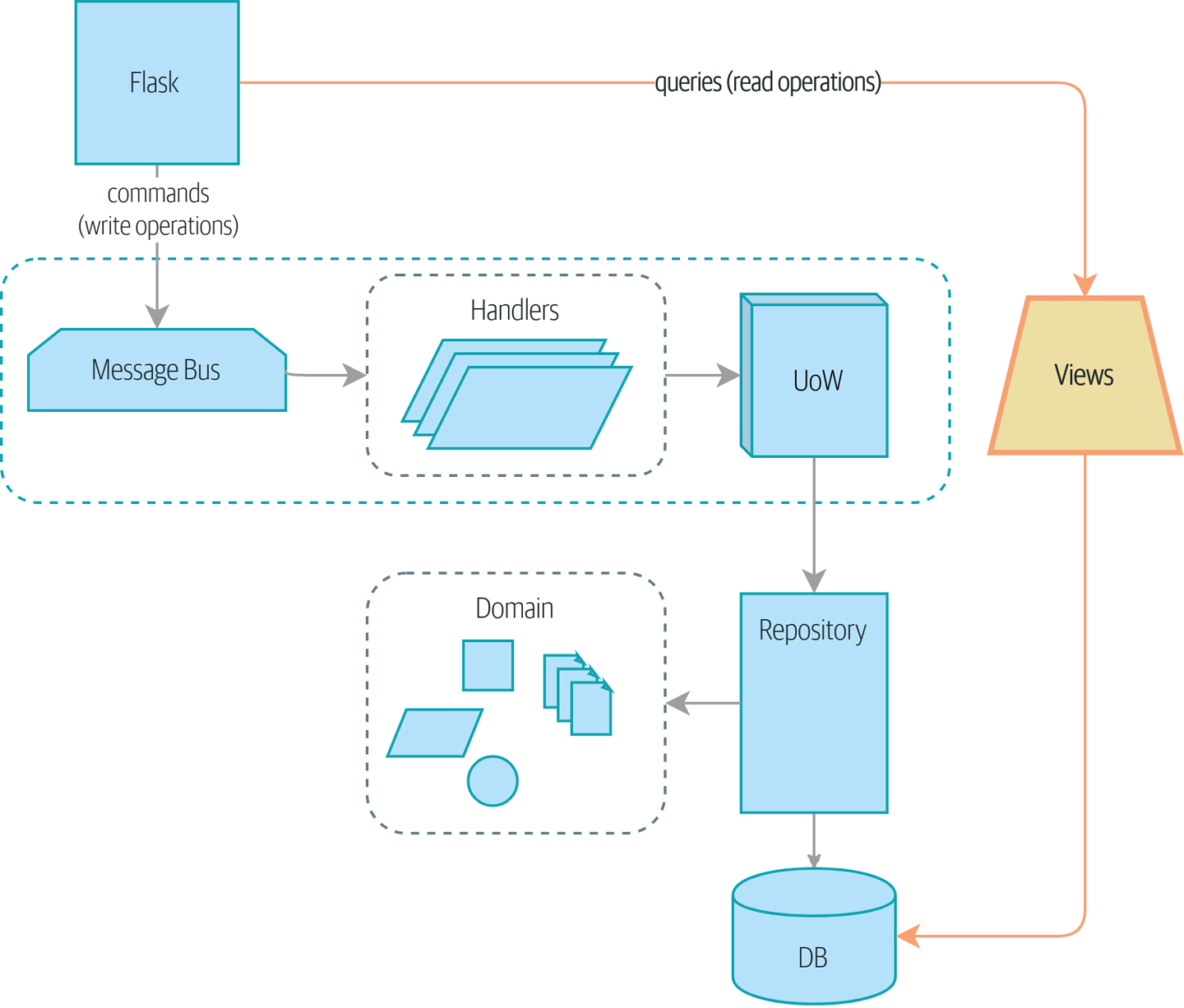
Separating reads from writes shows where we might end up.
|
Tip
|
The code for this chapter is in the chapter_12_cqrs branch on GitHub. git clone https://github.com/cosmicpython/code.git cd code git checkout chapter_12_cqrs # or to code along, checkout the previous chapter: git checkout chapter_11_external_events |
First, though, why bother?
Domain Models Are for Writing
We’ve spent a lot of time in this book talking about how to build software that enforces the rules of our domain. These rules, or constraints, will be different for every application, and they make up the interesting core of our systems.
In this book, we’ve set explicit constraints like "You can’t allocate more stock than is available," as well as implicit constraints like "Each order line is allocated to a single batch."
We wrote down these rules as unit tests at the beginning of the book:
def test_allocating_to_a_batch_reduces_the_available_quantity():
batch = Batch("batch-001", "SMALL-TABLE", qty=20, eta=date.today())
line = OrderLine("order-ref", "SMALL-TABLE", 2)
batch.allocate(line)
assert batch.available_quantity == 18
...
def test_cannot_allocate_if_available_smaller_than_required():
small_batch, large_line = make_batch_and_line("ELEGANT-LAMP", 2, 20)
assert small_batch.can_allocate(large_line) is FalseTo apply these rules properly, we needed to ensure that operations were consistent, and so we introduced patterns like Unit of Work and Aggregate that help us commit small chunks of work.
To communicate changes between those small chunks, we introduced the Domain Events pattern so we can write rules like "When stock is damaged or lost, adjust the available quantity on the batch, and reallocate orders if necessary."
All of this complexity exists so we can enforce rules when we change the state of our system. We’ve built a flexible set of tools for writing data.
What about reads, though?
Most Users Aren’t Going to Buy Your Furniture
At MADE.com, we have a system very like the allocation service. In a busy day, we might process one hundred orders in an hour, and we have a big gnarly system for allocating stock to those orders.
In that same busy day, though, we might have one hundred product views per second. Each time somebody visits a product page, or a product listing page, we need to figure out whether the product is still in stock and how long it will take us to deliver it.
The domain is the same—we’re concerned with batches of stock, and their arrival date, and the amount that’s still available—but the access pattern is very different. For example, our customers won’t notice if the query is a few seconds out of date, but if our allocate service is inconsistent, we’ll make a mess of their orders. We can take advantage of this difference by making our reads eventually consistent in order to make them perform better.
We can think of these requirements as forming two halves of a system: the read side and the write side, shown in Read versus write.
For the write side, our fancy domain architectural patterns help us to evolve our system over time, but the complexity we’ve built so far doesn’t buy anything for reading data. The service layer, the unit of work, and the clever domain model are just bloat.
| Read side | Write side | |
|---|---|---|
Behavior |
Simple read |
Complex business logic |
Cacheability |
Highly cacheable |
Uncacheable |
Consistency |
Can be stale |
Must be transactionally consistent |
Post/Redirect/Get and CQS
If you do web development, you’re probably familiar with the Post/Redirect/Get pattern. In this technique, a web endpoint accepts an HTTP POST and responds with a redirect to see the result. For example, we might accept a POST to /batches to create a new batch and redirect the user to /batches/123 to see their newly created batch.
This approach fixes the problems that arise when users refresh the results page in their browser or try to bookmark a results page. In the case of a refresh, it can lead to our users double-submitting data and thus buying two sofas when they needed only one. In the case of a bookmark, our hapless customers will end up with a broken page when they try to GET a POST endpoint.
Both these problems happen because we’re returning data in response to a write operation. Post/Redirect/Get sidesteps the issue by separating the read and write phases of our operation.
This technique is a simple example of command-query separation (CQS).[1] We follow one simple rule: functions should either modify state or answer questions, but never both. This makes software easier to reason about: we should always be able to ask, "Are the lights on?" without flicking the light switch.
|
Note
|
When building APIs, we can apply the same design technique by returning a 201 Created, or a 202 Accepted, with a Location header containing the URI of our new resources. What’s important here isn’t the status code we use but the logical separation of work into a write phase and a query phase. |
As you’ll see, we can use the CQS principle to make our systems faster and more
scalable, but first, let’s fix the CQS violation in our existing code. Ages
ago, we introduced an allocate endpoint that takes an order and calls our
service layer to allocate some stock. At the end of the call, we return a 200
OK and the batch ID. That’s led to some ugly design flaws so that we can get
the data we need. Let’s change it to return a simple OK message and instead
provide a new read-only endpoint to retrieve allocation state:
@pytest.mark.usefixtures("postgres_db")
@pytest.mark.usefixtures("restart_api")
def test_happy_path_returns_202_and_batch_is_allocated():
orderid = random_orderid()
sku, othersku = random_sku(), random_sku("other")
earlybatch = random_batchref(1)
laterbatch = random_batchref(2)
otherbatch = random_batchref(3)
api_client.post_to_add_batch(laterbatch, sku, 100, "2011-01-02")
api_client.post_to_add_batch(earlybatch, sku, 100, "2011-01-01")
api_client.post_to_add_batch(otherbatch, othersku, 100, None)
r = api_client.post_to_allocate(orderid, sku, qty=3)
assert r.status_code == 202
r = api_client.get_allocation(orderid)
assert r.ok
assert r.json() == [
{"sku": sku, "batchref": earlybatch},
]
@pytest.mark.usefixtures("postgres_db")
@pytest.mark.usefixtures("restart_api")
def test_unhappy_path_returns_400_and_error_message():
unknown_sku, orderid = random_sku(), random_orderid()
r = api_client.post_to_allocate(
orderid, unknown_sku, qty=20, expect_success=False
)
assert r.status_code == 400
assert r.json()["message"] == f"Invalid sku {unknown_sku}"
r = api_client.get_allocation(orderid)
assert r.status_code == 404OK, what might the Flask app look like?
from allocation import views
...
@app.route("/allocations/<orderid>", methods=["GET"])
def allocations_view_endpoint(orderid):
uow = unit_of_work.SqlAlchemyUnitOfWork()
result = views.allocations(orderid, uow) #(1)
if not result:
return "not found", 404
return jsonify(result), 200-
All right, a views.py, fair enough; we can keep read-only stuff in there, and it’ll be a real views.py, not like Django’s, something that knows how to build read-only views of our data…
Hold On to Your Lunch, Folks
Hmm, so we can probably just add a list method to our existing repository object:
from allocation.service_layer import unit_of_work
def allocations(orderid: str, uow: unit_of_work.SqlAlchemyUnitOfWork):
with uow:
results = uow.session.execute(
"""
SELECT ol.sku, b.reference
FROM allocations AS a
JOIN batches AS b ON a.batch_id = b.id
JOIN order_lines AS ol ON a.orderline_id = ol.id
WHERE ol.orderid = :orderid
""",
dict(orderid=orderid),
)
return [{"sku": sku, "batchref": batchref} for sku, batchref in results]Excuse me? Raw SQL?
If you’re anything like Harry encountering this pattern for the first time, you’ll be wondering what on earth Bob has been smoking. We’re hand-rolling our own SQL now, and converting database rows directly to dicts? After all the effort we put into building a nice domain model? And what about the Repository pattern? Isn’t that meant to be our abstraction around the database? Why don’t we reuse that?
Well, let’s explore that seemingly simpler alternative first, and see what it looks like in practice.
We’ll still keep our view in a separate views.py module; enforcing a clear distinction between reads and writes in your application is still a good idea. We apply command-query separation, and it’s easy to see which code modifies state (the event handlers) and which code just retrieves read-only state (the views).
|
Tip
|
Splitting out your read-only views from your state-modifying command and event handlers is probably a good idea, even if you don’t want to go to full-blown CQRS. |
Testing CQRS Views
Before we get into exploring various options, let’s talk about testing. Whichever approaches you decide to go for, you’re probably going to need at least one integration test. Something like this:
def test_allocations_view(sqlite_session_factory):
uow = unit_of_work.SqlAlchemyUnitOfWork(sqlite_session_factory)
messagebus.handle(commands.CreateBatch("sku1batch", "sku1", 50, None), uow) #(1)
messagebus.handle(commands.CreateBatch("sku2batch", "sku2", 50, today), uow)
messagebus.handle(commands.Allocate("order1", "sku1", 20), uow)
messagebus.handle(commands.Allocate("order1", "sku2", 20), uow)
# add a spurious batch and order to make sure we're getting the right ones
messagebus.handle(commands.CreateBatch("sku1batch-later", "sku1", 50, today), uow)
messagebus.handle(commands.Allocate("otherorder", "sku1", 30), uow)
messagebus.handle(commands.Allocate("otherorder", "sku2", 10), uow)
assert views.allocations("order1", uow) == [
{"sku": "sku1", "batchref": "sku1batch"},
{"sku": "sku2", "batchref": "sku2batch"},
]-
We do the setup for the integration test by using the public entrypoint to our application, the message bus. That keeps our tests decoupled from any implementation/infrastructure details about how things get stored.
"Obvious" Alternative 1: Using the Existing Repository
How about adding a helper method to our products repository?
from allocation import unit_of_work
def allocations(orderid: str, uow: unit_of_work.AbstractUnitOfWork):
with uow:
products = uow.products.for_order(orderid=orderid) #(1)
batches = [b for p in products for b in p.batches] #(2)
return [
{'sku': b.sku, 'batchref': b.reference}
for b in batches
if orderid in b.orderids #(3)
]-
Our repository returns
Productobjects, and we need to find all the products for the SKUs in a given order, so we’ll build a new helper method called.for_order()on the repository. -
Now we have products but we actually want batch references, so we get all the possible batches with a list comprehension.
-
We filter again to get just the batches for our specific order. That, in turn, relies on our
Batchobjects being able to tell us which order IDs it has allocated.
We implement that last using a .orderid property:
class Batch:
...
@property
def orderids(self):
return {l.orderid for l in self._allocations}You can start to see that reusing our existing repository and domain model classes is not as straightforward as you might have assumed. We’ve had to add new helper methods to both, and we’re doing a bunch of looping and filtering in Python, which is work that would be done much more efficiently by the database.
So yes, on the plus side we’re reusing our existing abstractions, but on the downside, it all feels quite clunky.
Your Domain Model Is Not Optimized for Read Operations
What we’re seeing here are the effects of having a domain model that is designed primarily for write operations, while our requirements for reads are often conceptually quite different.
This is the chin-stroking-architect’s justification for CQRS. As we’ve said before, a domain model is not a data model—we’re trying to capture the way the business works: workflow, rules around state changes, messages exchanged; concerns about how the system reacts to external events and user input. Most of this stuff is totally irrelevant for read-only operations.
|
Tip
|
This justification for CQRS is related to the justification for the Domain Model pattern. If you’re building a simple CRUD app, reads and writes are going to be closely related, so you don’t need a domain model or CQRS. But the more complex your domain, the more likely you are to need both. |
To make a facile point, your domain classes will have multiple methods for modifying state, and you won’t need any of them for read-only operations.
As the complexity of your domain model grows, you will find yourself making more and more choices about how to structure that model, which make it more and more awkward to use for read operations.
"Obvious" Alternative 2: Using the ORM
You may be thinking, OK, if our repository is clunky, and working with
Products is clunky, then I can at least use my ORM and work with Batches.
That’s what it’s for!
from allocation import unit_of_work, model
def allocations(orderid: str, uow: unit_of_work.AbstractUnitOfWork):
with uow:
batches = uow.session.query(model.Batch).join(
model.OrderLine, model.Batch._allocations
).filter(
model.OrderLine.orderid == orderid
)
return [
{"sku": b.sku, "batchref": b.batchref}
for b in batches
]But is that actually any easier to write or understand than the raw SQL version from the code example in Hold On to Your Lunch, Folks? It may not look too bad up there, but we can tell you it took several attempts, and plenty of digging through the SQLAlchemy docs. SQL is just SQL.
But the ORM can also expose us to performance problems.
SELECT N+1 and Other Performance Considerations
The so-called SELECT N+1
problem is a common performance problem with ORMs: when retrieving a list of
objects, your ORM will often perform an initial query to, say, get all the IDs
of the objects it needs, and then issue individual queries for each object to
retrieve their attributes. This is especially likely if there are any foreign-key relationships on your objects.
|
Note
|
In all fairness, we should say that SQLAlchemy is quite good at avoiding
the SELECT N+1 problem. It doesn’t display it in the preceding example, and
you can request eager loading
explicitly to avoid it when dealing with joined objects.
|
Beyond SELECT N+1, you may have other reasons for wanting to decouple the
way you persist state changes from the way that you retrieve current state.
A set of fully normalized relational tables is a good way to make sure that
write operations never cause data corruption. But retrieving data using lots
of joins can be slow. It’s common in such cases to add some denormalized views,
build read replicas, or even add caching layers.
Time to Completely Jump the Shark
On that note: have we convinced you that our raw SQL version isn’t so weird as it first seemed? Perhaps we were exaggerating for effect? Just you wait.
So, reasonable or not, that hardcoded SQL query is pretty ugly, right? What if we made it nicer…
def allocations(orderid: str, uow: unit_of_work.SqlAlchemyUnitOfWork):
with uow:
results = uow.session.execute(
"""
SELECT sku, batchref FROM allocations_view WHERE orderid = :orderid
""",
dict(orderid=orderid),
)
...…by keeping a totally separate, denormalized data store for our view model?
allocations_view = Table(
"allocations_view",
metadata,
Column("orderid", String(255)),
Column("sku", String(255)),
Column("batchref", String(255)),
)OK, nicer-looking SQL queries wouldn’t be a justification for anything really, but building a denormalized copy of your data that’s optimized for read operations isn’t uncommon, once you’ve reached the limits of what you can do with indexes.
Even with well-tuned indexes, a relational database uses a lot of CPU to perform
joins. The fastest queries will always be SELECT * from mytable WHERE key = :value.
More than raw speed, though, this approach buys us scale. When we’re writing data to a relational database, we need to make sure that we get a lock over the rows we’re changing so we don’t run into consistency problems.
If multiple clients are changing data at the same time, we’ll have weird race conditions. When we’re reading data, though, there’s no limit to the number of clients that can concurrently execute. For this reason, read-only stores can be horizontally scaled out.
|
Tip
|
Because read replicas can be inconsistent, there’s no limit to how many we can have. If you’re struggling to scale a system with a complex data store, ask whether you could build a simpler read model. |
Keeping the read model up to date is the challenge! Database views (materialized or otherwise) and triggers are a common solution, but that limits you to your database. We’d like to show you how to reuse our event-driven architecture instead.
Updating a Read Model Table Using an Event Handler
We add a second handler to the Allocated event:
EVENT_HANDLERS = {
events.Allocated: [
handlers.publish_allocated_event,
handlers.add_allocation_to_read_model,
],Here’s what our update-view-model code looks like:
def add_allocation_to_read_model(
event: events.Allocated,
uow: unit_of_work.SqlAlchemyUnitOfWork,
):
with uow:
uow.session.execute(
"""
INSERT INTO allocations_view (orderid, sku, batchref)
VALUES (:orderid, :sku, :batchref)
""",
dict(orderid=event.orderid, sku=event.sku, batchref=event.batchref),
)
uow.commit()Believe it or not, that will pretty much work! And it will work against the exact same integration tests as the rest of our options.
OK, you’ll also need to handle Deallocated:
events.Deallocated: [
handlers.remove_allocation_from_read_model,
handlers.reallocate
],
...
def remove_allocation_from_read_model(
event: events.Deallocated,
uow: unit_of_work.SqlAlchemyUnitOfWork,
):
with uow:
uow.session.execute(
"""
DELETE FROM allocations_view
WHERE orderid = :orderid AND sku = :sku
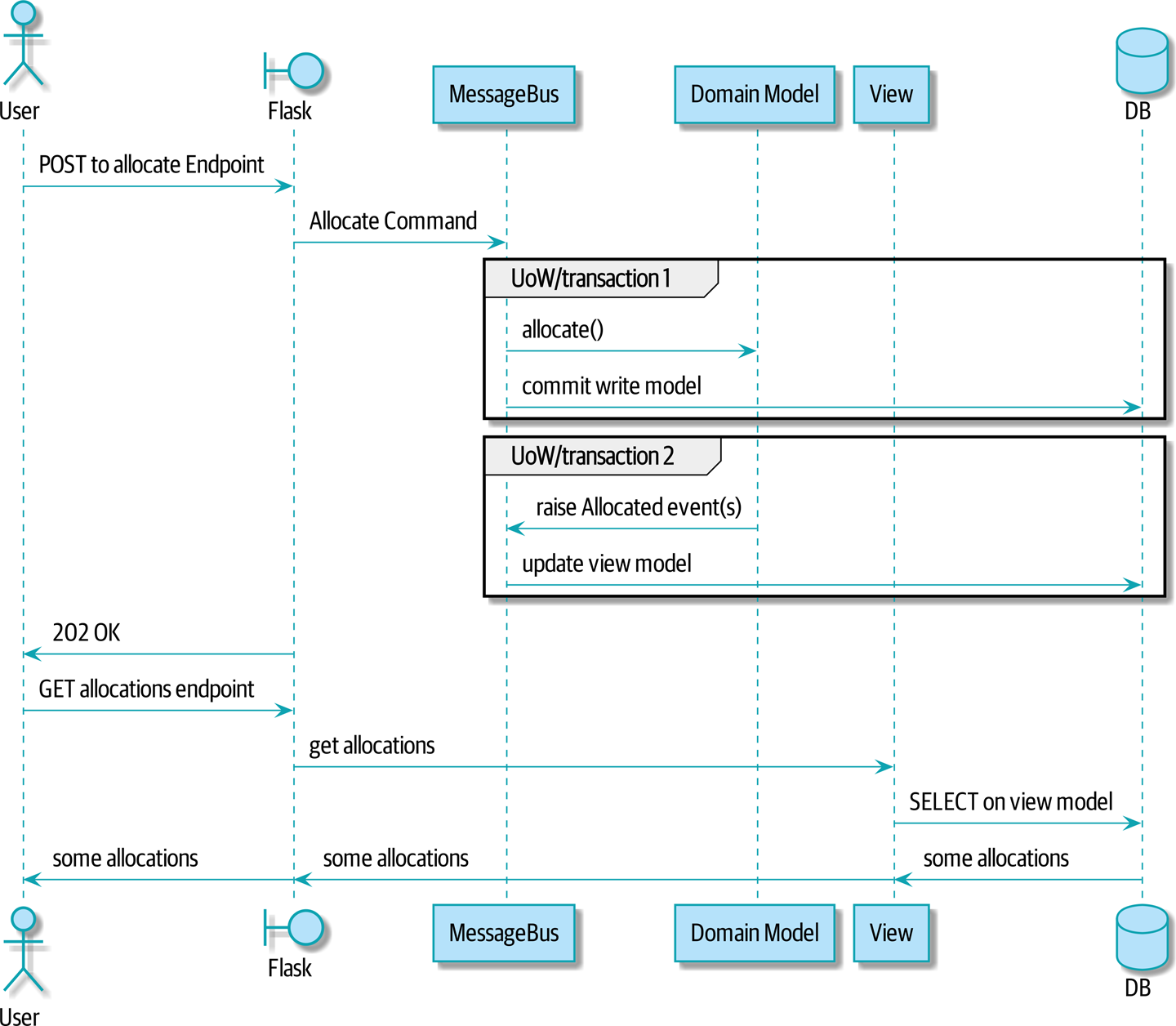
...Sequence diagram for read model shows the flow across the two requests.
[plantuml, apwp_1202, config=plantuml.cfg]
@startuml
scale 4
!pragma teoz true
actor User order 1
boundary Flask order 2
participant MessageBus order 3
participant "Domain Model" as Domain order 4
participant View order 9
database DB order 10
User -> Flask: POST to allocate Endpoint
Flask -> MessageBus : Allocate Command
group UoW/transaction 1
MessageBus -> Domain : allocate()
MessageBus -> DB: commit write model
end
group UoW/transaction 2
Domain -> MessageBus : raise Allocated event(s)
MessageBus -> DB : update view model
end
Flask -> User: 202 OK
User -> Flask: GET allocations endpoint
Flask -> View: get allocations
View -> DB: SELECT on view model
DB -> View: some allocations
& View -> Flask: some allocations
& Flask -> User: some allocations
@enduml
In Sequence diagram for read model, you can see two transactions in the POST/write operation, one to update the write model and one to update the read model, which the GET/read operation can use.
Changing Our Read Model Implementation Is Easy
Let’s see the flexibility that our event-driven model buys us in action, by seeing what happens if we ever decide we want to implement a read model by using a totally separate storage engine, Redis.
Just watch:
def add_allocation_to_read_model(event: events.Allocated, _):
redis_eventpublisher.update_readmodel(event.orderid, event.sku, event.batchref)
def remove_allocation_from_read_model(event: events.Deallocated, _):
redis_eventpublisher.update_readmodel(event.orderid, event.sku, None)The helpers in our Redis module are one-liners:
def update_readmodel(orderid, sku, batchref):
r.hset(orderid, sku, batchref)
def get_readmodel(orderid):
return r.hgetall(orderid)(Maybe the name redis_eventpublisher.py is a misnomer now, but you get the idea.)
And the view itself changes very slightly to adapt to its new backend:
def allocations(orderid: str):
batches = redis_eventpublisher.get_readmodel(orderid)
return [
{"batchref": b.decode(), "sku": s.decode()}
for s, b in batches.items()
]And the exact same integration tests that we had before still pass, because they are written at a level of abstraction that’s decoupled from the implementation: setup puts messages on the message bus, and the assertions are against our view.
|
Tip
|
Event handlers are a great way to manage updates to a read model, if you decide you need one. They also make it easy to change the implementation of that read model at a later date. |
Wrap-Up
Trade-offs of various view model options proposes some pros and cons for each of our options.
As it happens, the allocation service at MADE.com does use "full-blown" CQRS, with a read model stored in Redis, and even a second layer of cache provided by Varnish. But its use cases are quite a bit different from what we’ve shown here. For the kind of allocation service we’re building, it seems unlikely that you’d need to use a separate read model and event handlers for updating it.
But as your domain model becomes richer and more complex, a simplified read model become ever more compelling.
| Option | Pros | Cons |
|---|---|---|
Just use repositories |
Simple, consistent approach. |
Expect performance issues with complex query patterns. |
Use custom queries with your ORM |
Allows reuse of DB configuration and model definitions. |
Adds another query language with its own quirks and syntax. |
Use hand-rolled SQL to query your normal model tables |
Offers fine control over performance with a standard query syntax. |
Changes to DB schema have to be made to your hand-rolled queries and your ORM definitions. Highly normalized schemas may still have performance limitations. |
Add some extra (denormalized) tables to your DB as a read model |
A denormalized table can be much faster to query. If we update the normalized and denormalized ones in the same transaction, we will still have good guarantees of data consistency |
It will slow down writes slightly |
Create separate read stores with events |
Read-only copies are easy to scale out. Views can be constructed when data changes so that queries are as simple as possible. |
Complex technique. Harry will be forever suspicious of your tastes and motives. |
Often, your read operations will be acting on the same conceptual objects as your write model, so using the ORM, adding some read methods to your repositories, and using domain model classes for your read operations is just fine.
In our book example, the read operations act on quite different conceptual
entities to our domain model. The allocation service thinks in terms of
Batches for a single SKU, but users care about allocations for a whole order,
with multiple SKUs, so using the ORM ends up being a little awkward. We’d be
quite tempted to go with the raw-SQL view we showed right at the beginning of
the chapter.
On that note, let’s sally forth into our final chapter.