
8: Events and the Message Bus
So far we’ve spent a lot of time and energy on a simple problem that we could easily have solved with Django. You might be asking if the increased testability and expressiveness are really worth all the effort.
In practice, though, we find that it’s not the obvious features that make a mess of our codebases: it’s the goop around the edge. It’s reporting, and permissions, and workflows that touch a zillion objects.
Our example will be a typical notification requirement: when we can’t allocate an order because we’re out of stock, we should alert the buying team. They’ll go and fix the problem by buying more stock, and all will be well.
For a first version, our product owner says we can just send the alert by email.
Let’s see how our architecture holds up when we need to plug in some of the mundane stuff that makes up so much of our systems.
We’ll start by doing the simplest, most expeditious thing, and talk about why it’s exactly this kind of decision that leads us to the Big Ball of Mud.
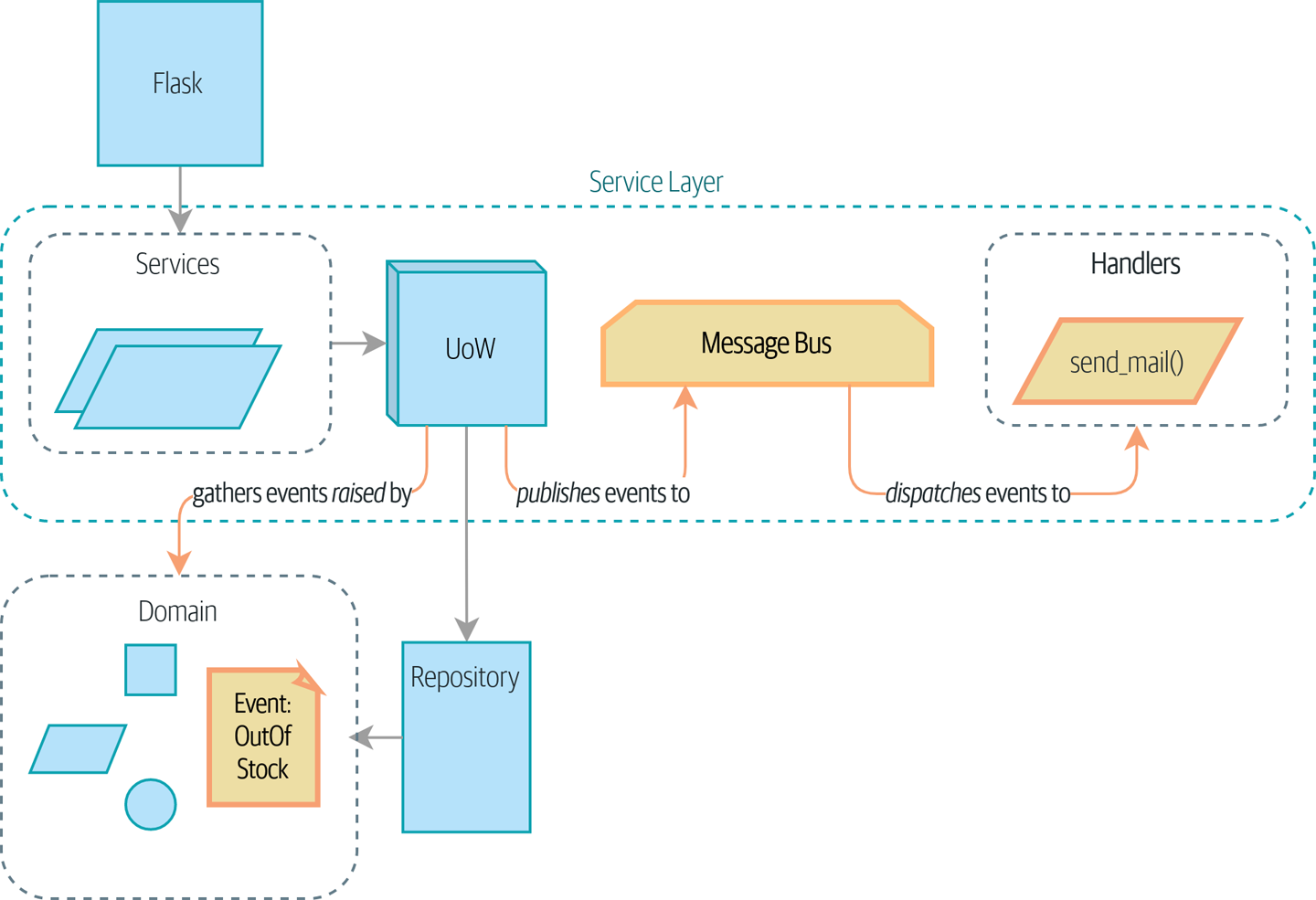
Then we’ll show how to use the Domain Events pattern to separate side effects from our use cases, and how to use a simple Message Bus pattern for triggering behavior based on those events. We’ll show a few options for creating those events and how to pass them to the message bus, and finally we’ll show how the Unit of Work pattern can be modified to connect the two together elegantly, as previewed in Events flowing through the system.
|
Tip
|
The code for this chapter is in the chapter_08_events_and_message_bus branch on GitHub: git clone https://github.com/cosmicpython/code.git cd code git checkout chapter_08_events_and_message_bus # or to code along, checkout the previous chapter: git checkout chapter_07_aggregate |
Avoiding Making a Mess
So. Email alerts when we run out of stock. When we have new requirements like ones that really have nothing to do with the core domain, it’s all too easy to start dumping these things into our web controllers.
First, Let’s Avoid Making a Mess of Our Web Controllers
As a one-off hack, this might be OK:
@app.route("/allocate", methods=["POST"])
def allocate_endpoint():
line = model.OrderLine(
request.json["orderid"],
request.json["sku"],
request.json["qty"],
)
try:
uow = unit_of_work.SqlAlchemyUnitOfWork()
batchref = services.allocate(line, uow)
except (model.OutOfStock, services.InvalidSku) as e:
send_mail(
"out of stock",
"stock_admin@made.com",
f"{line.orderid} - {line.sku}"
)
return {"message": str(e)}, 400
return {"batchref": batchref}, 201…but it’s easy to see how we can quickly end up in a mess by patching things up like this. Sending email isn’t the job of our HTTP layer, and we’d like to be able to unit test this new feature.
And Let’s Not Make a Mess of Our Model Either
Assuming we don’t want to put this code into our web controllers, because we want them to be as thin as possible, we may look at putting it right at the source, in the model:
def allocate(self, line: OrderLine) -> str:
try:
batch = next(b for b in sorted(self.batches) if b.can_allocate(line))
#...
except StopIteration:
email.send_mail("stock@made.com", f"Out of stock for {line.sku}")
raise OutOfStock(f"Out of stock for sku {line.sku}")But that’s even worse! We don’t want our model to have any dependencies on
infrastructure concerns like email.send_mail.
This email-sending thing is unwelcome goop messing up the nice clean flow of our system. What we’d like is to keep our domain model focused on the rule "You can’t allocate more stuff than is actually available."
Or the Service Layer!
The requirement "Try to allocate some stock, and send an email if it fails" is an example of workflow orchestration: it’s a set of steps that the system has to follow to achieve a goal.
We’ve written a service layer to manage orchestration for us, but even here the feature feels out of place:
def allocate(
orderid: str, sku: str, qty: int,
uow: unit_of_work.AbstractUnitOfWork,
) -> str:
line = OrderLine(orderid, sku, qty)
with uow:
product = uow.products.get(sku=line.sku)
if product is None:
raise InvalidSku(f"Invalid sku {line.sku}")
try:
batchref = product.allocate(line)
uow.commit()
return batchref
except model.OutOfStock:
email.send_mail("stock@made.com", f"Out of stock for {line.sku}")
raiseCatching an exception and reraising it? It could be worse, but it’s definitely making us unhappy. Why is it so hard to find a suitable home for this code?
Single Responsibility Principle
Really, this is a violation of the single responsibility principle (SRP).[1]
Our use case is allocation. Our endpoint, service function, and domain methods
are all called allocate, not
allocate_and_send_mail_if_out_of_stock.
|
Tip
|
Rule of thumb: if you can’t describe what your function does without using words like "then" or "and," you might be violating the SRP. |
One formulation of the SRP is that each class should have only a single reason
to change. When we switch from email to SMS, we shouldn’t have to update our
allocate() function, because that’s clearly a separate responsibility.
To solve the problem, we’re going to split the orchestration into separate steps so that the different concerns don’t get tangled up.[2] The domain model’s job is to know that we’re out of stock, but the responsibility of sending an alert belongs elsewhere. We should be able to turn this feature on or off, or to switch to SMS notifications instead, without needing to change the rules of our domain model.
We’d also like to keep the service layer free of implementation details. We want to apply the dependency inversion principle to notifications so that our service layer depends on an abstraction, in the same way as we avoid depending on the database by using a unit of work.
All Aboard the Message Bus!
The patterns we’re going to introduce here are Domain Events and the Message Bus. We can implement them in a few ways, so we’ll show a couple before settling on the one we like most.
The Model Records Events
First, rather than being concerned about emails, our model will be in charge of recording events—facts about things that have happened. We’ll use a message bus to respond to events and invoke a new operation.
Events Are Simple Dataclasses
An event is a kind of value object. Events don’t have any behavior, because they’re pure data structures. We always name events in the language of the domain, and we think of them as part of our domain model.
We could store them in model.py, but we may as well keep them in their own file (this might be a good time to consider refactoring out a directory called domain so that we have domain/model.py and domain/events.py):
from dataclasses import dataclass
class Event: #(1)
pass
@dataclass
class OutOfStock(Event): #(2)
sku: str-
Once we have a number of events, we’ll find it useful to have a parent class that can store common attributes. It’s also useful for type hints in our message bus, as you’ll see shortly.
-
dataclassesare great for domain events too.
The Model Raises Events
When our domain model records a fact that happened, we say it raises an event.
Here’s what it will look like from the outside; if we ask Product to allocate
but it can’t, it should raise an event:
def test_records_out_of_stock_event_if_cannot_allocate():
batch = Batch("batch1", "SMALL-FORK", 10, eta=today)
product = Product(sku="SMALL-FORK", batches=[batch])
product.allocate(OrderLine("order1", "SMALL-FORK", 10))
allocation = product.allocate(OrderLine("order2", "SMALL-FORK", 1))
assert product.events[-1] == events.OutOfStock(sku="SMALL-FORK") #(1)
assert allocation is None-
Our aggregate will expose a new attribute called
.eventsthat will contain a list of facts about what has happened, in the form ofEventobjects.
Here’s what the model looks like on the inside:
class Product:
def __init__(self, sku: str, batches: List[Batch], version_number: int = 0):
self.sku = sku
self.batches = batches
self.version_number = version_number
self.events = [] # type: List[events.Event] #(1)
def allocate(self, line: OrderLine) -> str:
try:
#...
except StopIteration:
self.events.append(events.OutOfStock(line.sku)) #(2)
# raise OutOfStock(f"Out of stock for sku {line.sku}") #(3)
return None-
Here’s our new
.eventsattribute in use. -
Rather than invoking some email-sending code directly, we record those events at the place they occur, using only the language of the domain.
-
We’re also going to stop raising an exception for the out-of-stock case. The event will do the job the exception was doing.
|
Note
|
We’re actually addressing a code smell we had until now, which is that we were using exceptions for control flow. In general, if you’re implementing domain events, don’t raise exceptions to describe the same domain concept. As you’ll see later when we handle events in the Unit of Work pattern, it’s confusing to have to reason about events and exceptions together. |
The Message Bus Maps Events to Handlers
A message bus basically says, "When I see this event, I should invoke the following handler function." In other words, it’s a simple publish-subscribe system. Handlers are subscribed to receive events, which we publish to the bus. It sounds harder than it is, and we usually implement it with a dict:
def handle(event: events.Event):
for handler in HANDLERS[type(event)]:
handler(event)
def send_out_of_stock_notification(event: events.OutOfStock):
email.send_mail(
"stock@made.com",
f"Out of stock for {event.sku}",
)
HANDLERS = {
events.OutOfStock: [send_out_of_stock_notification],
} # type: Dict[Type[events.Event], List[Callable]]|
Note
|
Note that the message bus as implemented doesn’t give us concurrency because only one handler will run at a time. Our objective isn’t to support parallel threads but to separate tasks conceptually, and to keep each UoW as small as possible. This helps us to understand the codebase because the "recipe" for how to run each use case is written in a single place. See the following sidebar. |
Option 1: The Service Layer Takes Events from the Model and Puts Them on the Message Bus
Our domain model raises events, and our message bus will call the right handlers whenever an event happens. Now all we need is to connect the two. We need something to catch events from the model and pass them to the message bus—the publishing step.
The simplest way to do this is by adding some code into our service layer:
from . import messagebus
...
def allocate(
orderid: str, sku: str, qty: int,
uow: unit_of_work.AbstractUnitOfWork,
) -> str:
line = OrderLine(orderid, sku, qty)
with uow:
product = uow.products.get(sku=line.sku)
if product is None:
raise InvalidSku(f"Invalid sku {line.sku}")
try: #(1)
batchref = product.allocate(line)
uow.commit()
return batchref
finally: #(1)
messagebus.handle(product.events) #(2)-
We keep the
try/finallyfrom our ugly earlier implementation (we haven’t gotten rid of all exceptions yet, justOutOfStock). -
But now, instead of depending directly on an email infrastructure, the service layer is just in charge of passing events from the model up to the message bus.
That already avoids some of the ugliness that we had in our naive implementation, and we have several systems that work like this one, in which the service layer explicitly collects events from aggregates and passes them to the message bus.
Option 2: The Service Layer Raises Its Own Events
Another variant on this that we’ve used is to have the service layer in charge of creating and raising events directly, rather than having them raised by the domain model:
def allocate(
orderid: str, sku: str, qty: int,
uow: unit_of_work.AbstractUnitOfWork,
) -> str:
line = OrderLine(orderid, sku, qty)
with uow:
product = uow.products.get(sku=line.sku)
if product is None:
raise InvalidSku(f"Invalid sku {line.sku}")
batchref = product.allocate(line)
uow.commit() #(1)
if batchref is None:
messagebus.handle(events.OutOfStock(line.sku))
return batchref-
As before, we commit even if we fail to allocate because the code is simpler this way and it’s easier to reason about: we always commit unless something goes wrong. Committing when we haven’t changed anything is safe and keeps the code uncluttered.
Again, we have applications in production that implement the pattern in this way. What works for you will depend on the particular trade-offs you face, but we’d like to show you what we think is the most elegant solution, in which we put the unit of work in charge of collecting and raising events.
Option 3: The UoW Publishes Events to the Message Bus
The UoW already has a try/finally, and it knows about all the aggregates
currently in play because it provides access to the repository. So it’s
a good place to spot events and pass them to the message bus:
class AbstractUnitOfWork(abc.ABC):
...
def commit(self):
self._commit() #(1)
self.publish_events() #(2)
def publish_events(self): #(2)
for product in self.products.seen: #(3)
while product.events:
event = product.events.pop(0)
messagebus.handle(event)
@abc.abstractmethod
def _commit(self):
raise NotImplementedError
...
class SqlAlchemyUnitOfWork(AbstractUnitOfWork):
...
def _commit(self): #(1)
self.session.commit()-
We’ll change our commit method to require a private
._commit()method from subclasses. -
After committing, we run through all the objects that our repository has seen and pass their events to the message bus.
-
That relies on the repository keeping track of aggregates that have been loaded using a new attribute,
.seen, as you’ll see in the next listing.
|
Note
|
Are you wondering what happens if one of the handlers fails? We’ll discuss error handling in detail in [chapter_10_commands]. |
class AbstractRepository(abc.ABC):
def __init__(self):
self.seen = set() # type: Set[model.Product] #(1)
def add(self, product: model.Product): #(2)
self._add(product)
self.seen.add(product)
def get(self, sku) -> model.Product: #(3)
product = self._get(sku)
if product:
self.seen.add(product)
return product
@abc.abstractmethod
def _add(self, product: model.Product): #(2)
raise NotImplementedError
@abc.abstractmethod #(3)
def _get(self, sku) -> model.Product:
raise NotImplementedError
class SqlAlchemyRepository(AbstractRepository):
def __init__(self, session):
super().__init__()
self.session = session
def _add(self, product): #(2)
self.session.add(product)
def _get(self, sku): #(3)
return self.session.query(model.Product).filter_by(sku=sku).first()-
For the UoW to be able to publish new events, it needs to be able to ask the repository for which
Productobjects have been used during this session. We use asetcalled.seento store them. That means our implementations need to callsuper().__init__(). -
The parent
add()method adds things to.seen, and now requires subclasses to implement._add(). -
Similarly,
.get()delegates to a._get()function, to be implemented by subclasses, in order to capture objects seen.
|
Note
|
The use of ._underscorey() methods and subclassing is definitely not
the only way you could implement these patterns. Have a go at the
"Exercise for the Reader" in this chapter and experiment
with some alternatives.
|
After the UoW and repository collaborate in this way to automatically keep track of live objects and process their events, the service layer can be totally free of event-handling concerns:
def allocate(
orderid: str, sku: str, qty: int,
uow: unit_of_work.AbstractUnitOfWork,
) -> str:
line = OrderLine(orderid, sku, qty)
with uow:
product = uow.products.get(sku=line.sku)
if product is None:
raise InvalidSku(f"Invalid sku {line.sku}")
batchref = product.allocate(line)
uow.commit()
return batchref
We do also have to remember to change the fakes in the service layer and make them
call super() in the right places, and to implement underscorey methods, but the
changes are minimal:
class FakeRepository(repository.AbstractRepository):
def __init__(self, products):
super().__init__()
self._products = set(products)
def _add(self, product):
self._products.add(product)
def _get(self, sku):
return next((p for p in self._products if p.sku == sku), None)
...
class FakeUnitOfWork(unit_of_work.AbstractUnitOfWork):
...
def _commit(self):
self.committed = TrueYou might be starting to worry that maintaining these fakes is going to be a maintenance burden. There’s no doubt that it is work, but in our experience it’s not a lot of work. Once your project is up and running, the interface for your repository and UoW abstractions really don’t change much. And if you’re using ABCs, they’ll help remind you when things get out of sync.
Wrap-Up
Domain events give us a way to handle workflows in our system. We often find, listening to our domain experts, that they express requirements in a causal or temporal way—for example, "When we try to allocate stock but there’s none available, then we should send an email to the buying team."
The magic words "When X, then Y" often tell us about an event that we can make concrete in our system. Treating events as first-class things in our model helps us make our code more testable and observable, and it helps isolate concerns.
And Domain events: the trade-offs shows the trade-offs as we see them.
| Pros | Cons |
|---|---|
|
|
Events are useful for more than just sending email, though. In [chapter_07_aggregate] we spent a lot of time convincing you that you should define aggregates, or boundaries where we guarantee consistency. People often ask, "What should I do if I need to change multiple aggregates as part of a request?" Now we have the tools we need to answer that question.
If we have two things that can be transactionally isolated (e.g., an order and a product), then we can make them eventually consistent by using events. When an order is canceled, we should find the products that were allocated to it and remove the allocations.
In [chapter_09_all_messagebus], we’ll look at this idea in more detail as we build a more complex workflow with our new message bus.