
4: Our First Use Case: Flask API and Service Layer
Back to our allocations project! Before: we drive our app by talking to repositories and the domain model shows the point we reached at the end of [chapter_02_repository], which covered the Repository pattern.
In this chapter, we discuss the differences between orchestration logic, business logic, and interfacing code, and we introduce the Service Layer pattern to take care of orchestrating our workflows and defining the use cases of our system.
We’ll also discuss testing: by combining the Service Layer with our repository abstraction over the database, we’re able to write fast tests, not just of our domain model but of the entire workflow for a use case.
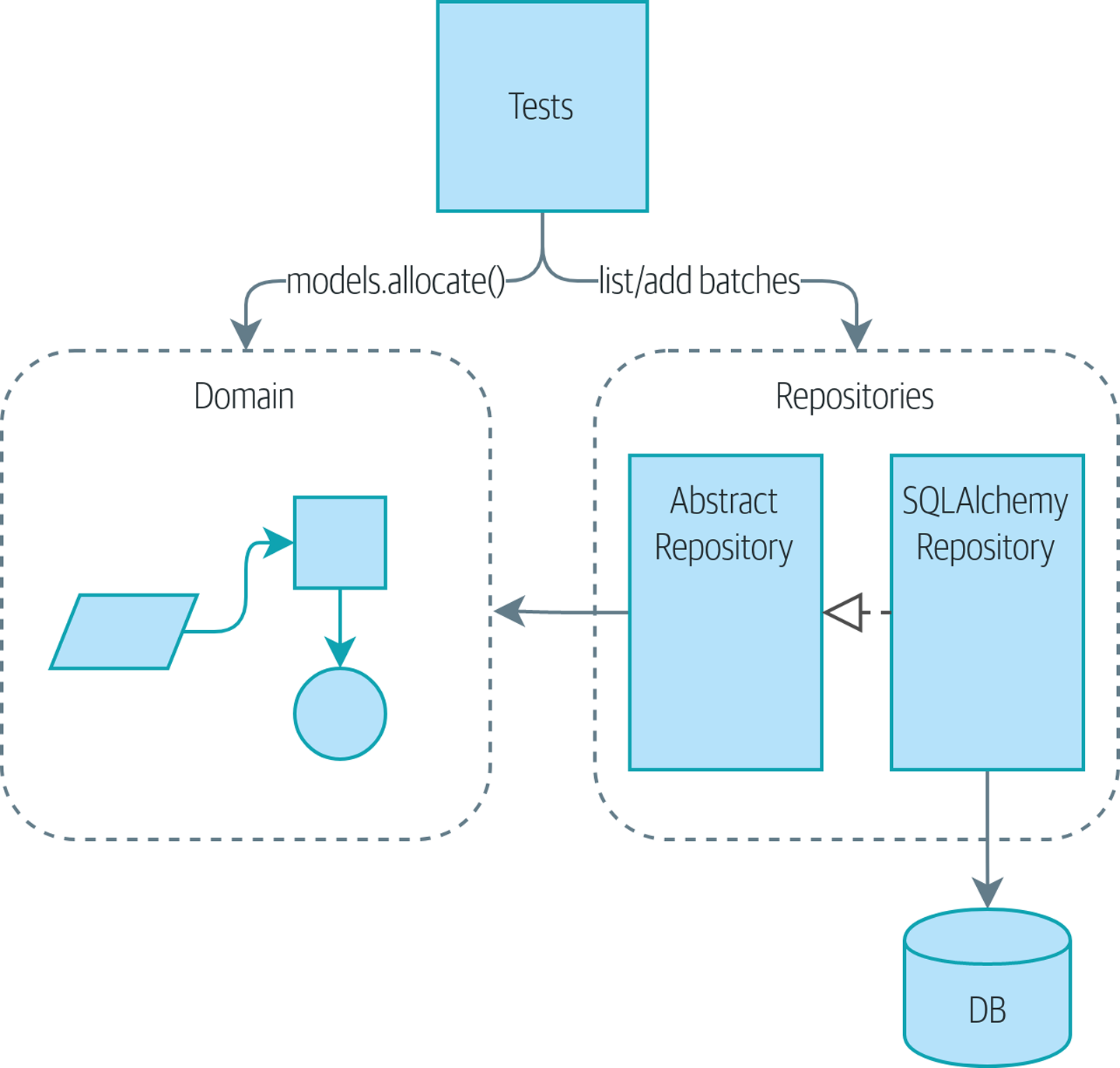
The service layer will become the main way into our app shows what we’re aiming for: we’re going to
add a Flask API that will talk to the service layer, which will serve as the
entrypoint to our domain model. Because our service layer depends on the
AbstractRepository, we can unit test it by using FakeRepository but run our production code using SqlAlchemyRepository.
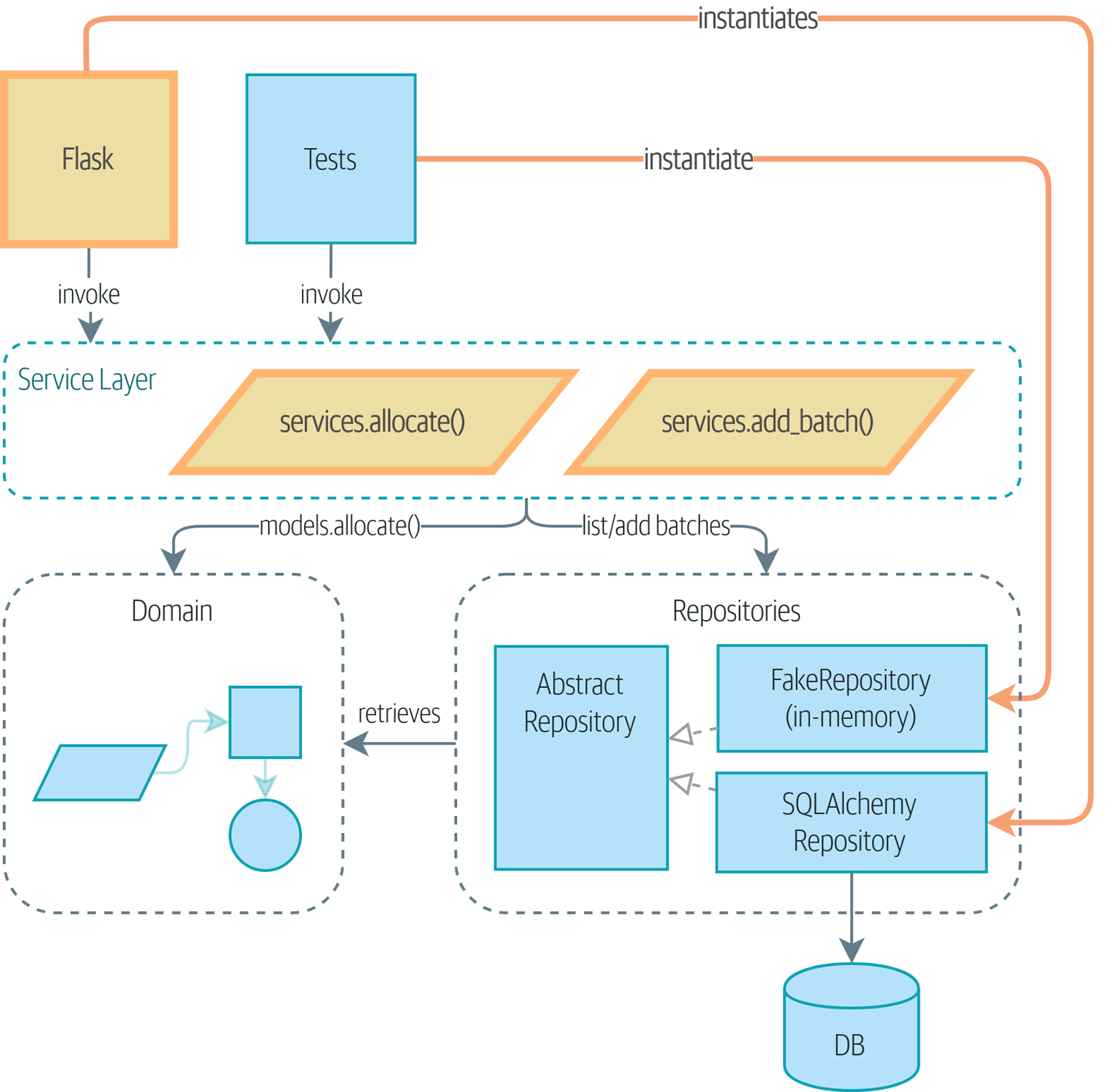
In our diagrams, we are using the convention that new components are highlighted with bold text/lines (and yellow/orange color, if you’re reading a digital version).
|
Tip
|
The code for this chapter is in the chapter_04_service_layer branch on GitHub: git clone https://github.com/cosmicpython/code.git cd code git checkout chapter_04_service_layer # or to code along, checkout Chapter 2: git checkout chapter_02_repository |
Connecting Our Application to the Real World
Like any good agile team, we’re hustling to try to get an MVP out and in front of the users to start gathering feedback. We have the core of our domain model and the domain service we need to allocate orders, and we have the repository interface for permanent storage.
Let’s plug all the moving parts together as quickly as we can and then refactor toward a cleaner architecture. Here’s our plan:
-
Use Flask to put an API endpoint in front of our
allocatedomain service. Wire up the database session and our repository. Test it with an end-to-end test and some quick-and-dirty SQL to prepare test data. -
Refactor out a service layer that can serve as an abstraction to capture the use case and that will sit between Flask and our domain model. Build some service-layer tests and show how they can use
FakeRepository. -
Experiment with different types of parameters for our service layer functions; show that using primitive data types allows the service layer’s clients (our tests and our Flask API) to be decoupled from the model layer.
A First End-to-End Test
No one is interested in getting into a long terminology debate about what counts as an end-to-end (E2E) test versus a functional test versus an acceptance test versus an integration test versus a unit test. Different projects need different combinations of tests, and we’ve seen perfectly successful projects just split things into "fast tests" and "slow tests."
For now, we want to write one or maybe two tests that are going to exercise a "real" API endpoint (using HTTP) and talk to a real database. Let’s call them end-to-end tests because it’s one of the most self-explanatory names.
The following shows a first cut:
@pytest.mark.usefixtures("restart_api")
def test_api_returns_allocation(add_stock):
sku, othersku = random_sku(), random_sku("other") #(1)
earlybatch = random_batchref(1)
laterbatch = random_batchref(2)
otherbatch = random_batchref(3)
add_stock( #(2)
[
(laterbatch, sku, 100, "2011-01-02"),
(earlybatch, sku, 100, "2011-01-01"),
(otherbatch, othersku, 100, None),
]
)
data = {"orderid": random_orderid(), "sku": sku, "qty": 3}
url = config.get_api_url() #(3)
r = requests.post(f"{url}/allocate", json=data)
assert r.status_code == 201
assert r.json()["batchref"] == earlybatch-
random_sku(),random_batchref(), and so on are little helper functions that generate randomized characters by using theuuidmodule. Because we’re running against an actual database now, this is one way to prevent various tests and runs from interfering with each other. -
add_stockis a helper fixture that just hides away the details of manually inserting rows into the database using SQL. We’ll show a nicer way of doing this later in the chapter. -
config.py is a module in which we keep configuration information.
Everyone solves these problems in different ways, but you’re going to need some way of spinning up Flask, possibly in a container, and of talking to a Postgres database. If you want to see how we did it, check out [appendix_project_structure].
The Straightforward Implementation
Implementing things in the most obvious way, you might get something like this:
from flask import Flask, request
from sqlalchemy import create_engine
from sqlalchemy.orm import sessionmaker
import config
import model
import orm
import repository
orm.start_mappers()
get_session = sessionmaker(bind=create_engine(config.get_postgres_uri()))
app = Flask(__name__)
@app.route("/allocate", methods=["POST"])
def allocate_endpoint():
session = get_session()
batches = repository.SqlAlchemyRepository(session).list()
line = model.OrderLine(
request.json["orderid"], request.json["sku"], request.json["qty"],
)
batchref = model.allocate(line, batches)
return {"batchref": batchref}, 201So far, so good. No need for too much more of your "architecture astronaut" nonsense, Bob and Harry, you may be thinking.
But hang on a minute—there’s no commit. We’re not actually saving our allocation to the database. Now we need a second test, either one that will inspect the database state after (not very black-boxy), or maybe one that checks that we can’t allocate a second line if a first should have already depleted the batch:
@pytest.mark.usefixtures("restart_api")
def test_allocations_are_persisted(add_stock):
sku = random_sku()
batch1, batch2 = random_batchref(1), random_batchref(2)
order1, order2 = random_orderid(1), random_orderid(2)
add_stock(
[(batch1, sku, 10, "2011-01-01"), (batch2, sku, 10, "2011-01-02"),]
)
line1 = {"orderid": order1, "sku": sku, "qty": 10}
line2 = {"orderid": order2, "sku": sku, "qty": 10}
url = config.get_api_url()
# first order uses up all stock in batch 1
r = requests.post(f"{url}/allocate", json=line1)
assert r.status_code == 201
assert r.json()["batchref"] == batch1
# second order should go to batch 2
r = requests.post(f"{url}/allocate", json=line2)
assert r.status_code == 201
assert r.json()["batchref"] == batch2Not quite so lovely, but that will force us to add the commit.
Error Conditions That Require Database Checks
If we keep going like this, though, things are going to get uglier and uglier.
Suppose we want to add a bit of error handling. What if the domain raises an error, for a SKU that’s out of stock? Or what about a SKU that doesn’t even exist? That’s not something the domain even knows about, nor should it. It’s more of a sanity check that we should implement at the database layer, before we even invoke the domain service.
Now we’re looking at two more end-to-end tests:
@pytest.mark.usefixtures("restart_api")
def test_400_message_for_out_of_stock(add_stock): #(1)
sku, small_batch, large_order = random_sku(), random_batchref(), random_orderid()
add_stock(
[(small_batch, sku, 10, "2011-01-01"),]
)
data = {"orderid": large_order, "sku": sku, "qty": 20}
url = config.get_api_url()
r = requests.post(f"{url}/allocate", json=data)
assert r.status_code == 400
assert r.json()["message"] == f"Out of stock for sku {sku}"
@pytest.mark.usefixtures("restart_api")
def test_400_message_for_invalid_sku(): #(2)
unknown_sku, orderid = random_sku(), random_orderid()
data = {"orderid": orderid, "sku": unknown_sku, "qty": 20}
url = config.get_api_url()
r = requests.post(f"{url}/allocate", json=data)
assert r.status_code == 400
assert r.json()["message"] == f"Invalid sku {unknown_sku}"-
In the first test, we’re trying to allocate more units than we have in stock.
-
In the second, the SKU just doesn’t exist (because we never called
add_stock), so it’s invalid as far as our app is concerned.
And sure, we could implement it in the Flask app too:
def is_valid_sku(sku, batches):
return sku in {b.sku for b in batches}
@app.route("/allocate", methods=["POST"])
def allocate_endpoint():
session = get_session()
batches = repository.SqlAlchemyRepository(session).list()
line = model.OrderLine(
request.json["orderid"], request.json["sku"], request.json["qty"],
)
if not is_valid_sku(line.sku, batches):
return {"message": f"Invalid sku {line.sku}"}, 400
try:
batchref = model.allocate(line, batches)
except model.OutOfStock as e:
return {"message": str(e)}, 400
session.commit()
return {"batchref": batchref}, 201But our Flask app is starting to look a bit unwieldy. And our number of E2E tests is starting to get out of control, and soon we’ll end up with an inverted test pyramid (or "ice-cream cone model," as Bob likes to call it).
Introducing a Service Layer, and Using FakeRepository to Unit Test It
If we look at what our Flask app is doing, there’s quite a lot of what we might call orchestration—fetching stuff out of our repository, validating our input against database state, handling errors, and committing in the happy path. Most of these things don’t have anything to do with having a web API endpoint (you’d need them if you were building a CLI, for example; see [appendix_csvs]), and they’re not really things that need to be tested by end-to-end tests.
It often makes sense to split out a service layer, sometimes called an orchestration layer or a use-case layer.
Do you remember the FakeRepository that we prepared in [chapter_03_abstractions]?
class FakeRepository(repository.AbstractRepository):
def __init__(self, batches):
self._batches = set(batches)
def add(self, batch):
self._batches.add(batch)
def get(self, reference):
return next(b for b in self._batches if b.reference == reference)
def list(self):
return list(self._batches)Here’s where it will come in useful; it lets us test our service layer with nice, fast unit tests:
def test_returns_allocation():
line = model.OrderLine("o1", "COMPLICATED-LAMP", 10)
batch = model.Batch("b1", "COMPLICATED-LAMP", 100, eta=None)
repo = FakeRepository([batch]) #(1)
result = services.allocate(line, repo, FakeSession()) #(2) (3)
assert result == "b1"
def test_error_for_invalid_sku():
line = model.OrderLine("o1", "NONEXISTENTSKU", 10)
batch = model.Batch("b1", "AREALSKU", 100, eta=None)
repo = FakeRepository([batch]) #(1)
with pytest.raises(services.InvalidSku, match="Invalid sku NONEXISTENTSKU"):
services.allocate(line, repo, FakeSession()) #(2) (3)-
FakeRepositoryholds theBatchobjects that will be used by our test. -
Our services module (services.py) will define an
allocate()service-layer function. It will sit between ourallocate_endpoint()function in the API layer and theallocate()domain service function from our domain model.[1] -
We also need a
FakeSessionto fake out the database session, as shown in the following code snippet.
class FakeSession:
committed = False
def commit(self):
self.committed = TrueThis fake session is only a temporary solution. We’ll get rid of it and make
things even nicer soon, in [chapter_06_uow]. But in the meantime
the fake .commit() lets us migrate a third test from the E2E layer:
def test_commits():
line = model.OrderLine("o1", "OMINOUS-MIRROR", 10)
batch = model.Batch("b1", "OMINOUS-MIRROR", 100, eta=None)
repo = FakeRepository([batch])
session = FakeSession()
services.allocate(line, repo, session)
assert session.committed is TrueA Typical Service Function
We’ll write a service function that looks something like this:
class InvalidSku(Exception):
pass
def is_valid_sku(sku, batches):
return sku in {b.sku for b in batches}
def allocate(line: OrderLine, repo: AbstractRepository, session) -> str:
batches = repo.list() #(1)
if not is_valid_sku(line.sku, batches): #(2)
raise InvalidSku(f"Invalid sku {line.sku}")
batchref = model.allocate(line, batches) #(3)
session.commit() #(4)
return batchrefTypical service-layer functions have similar steps:
-
We fetch some objects from the repository.
-
We make some checks or assertions about the request against the current state of the world.
-
We call a domain service.
-
If all is well, we save/update any state we’ve changed.
That last step is a little unsatisfactory at the moment, as our service layer is tightly coupled to our database layer. We’ll improve that in [chapter_06_uow] with the Unit of Work pattern.
But the essentials of the service layer are there, and our Flask app now looks a lot cleaner:
@app.route("/allocate", methods=["POST"])
def allocate_endpoint():
session = get_session() #(1)
repo = repository.SqlAlchemyRepository(session) #(1)
line = model.OrderLine(
request.json["orderid"], request.json["sku"], request.json["qty"], #(2)
)
try:
batchref = services.allocate(line, repo, session) #(2)
except (model.OutOfStock, services.InvalidSku) as e:
return {"message": str(e)}, 400 #(3)
return {"batchref": batchref}, 201 #(3)-
We instantiate a database session and some repository objects.
-
We extract the user’s commands from the web request and pass them to the service layer.
-
We return some JSON responses with the appropriate status codes.
The responsibilities of the Flask app are just standard web stuff: per-request session management, parsing information out of POST parameters, response status codes, and JSON. All the orchestration logic is in the use case/service layer, and the domain logic stays in the domain.
Finally, we can confidently strip down our E2E tests to just two, one for the happy path and one for the unhappy path:
@pytest.mark.usefixtures("restart_api")
def test_happy_path_returns_201_and_allocated_batch(add_stock):
sku, othersku = random_sku(), random_sku("other")
earlybatch = random_batchref(1)
laterbatch = random_batchref(2)
otherbatch = random_batchref(3)
add_stock(
[
(laterbatch, sku, 100, "2011-01-02"),
(earlybatch, sku, 100, "2011-01-01"),
(otherbatch, othersku, 100, None),
]
)
data = {"orderid": random_orderid(), "sku": sku, "qty": 3}
url = config.get_api_url()
r = requests.post(f"{url}/allocate", json=data)
assert r.status_code == 201
assert r.json()["batchref"] == earlybatch
@pytest.mark.usefixtures("restart_api")
def test_unhappy_path_returns_400_and_error_message():
unknown_sku, orderid = random_sku(), random_orderid()
data = {"orderid": orderid, "sku": unknown_sku, "qty": 20}
url = config.get_api_url()
r = requests.post(f"{url}/allocate", json=data)
assert r.status_code == 400
assert r.json()["message"] == f"Invalid sku {unknown_sku}"We’ve successfully split our tests into two broad categories: tests about web stuff, which we implement end to end; and tests about orchestration stuff, which we can test against the service layer in memory.
Why Is Everything Called a Service?
Some of you are probably scratching your heads at this point trying to figure out exactly what the difference is between a domain service and a service layer.
We’re sorry—we didn’t choose the names, or we’d have much cooler and friendlier ways to talk about this stuff.
We’re using two things called a service in this chapter. The first is an application service (our service layer). Its job is to handle requests from the outside world and to orchestrate an operation. What we mean is that the service layer drives the application by following a bunch of simple steps:
-
Get some data from the database
-
Update the domain model
-
Persist any changes
This is the kind of boring work that has to happen for every operation in your system, and keeping it separate from business logic helps to keep things tidy.
The second type of service is a domain service. This is the name for a piece of
logic that belongs in the domain model but doesn’t sit naturally inside a
stateful entity or value object. For example, if you were building a shopping
cart application, you might choose to build taxation rules as a domain service.
Calculating tax is a separate job from updating the cart, and it’s an important
part of the model, but it doesn’t seem right to have a persisted entity for
the job. Instead a stateless TaxCalculator class or a calculate_tax function
can do the job.
Putting Things in Folders to See Where It All Belongs
As our application gets bigger, we’ll need to keep tidying our directory structure. The layout of our project gives us useful hints about what kinds of object we’ll find in each file.
Here’s one way we could organize things:
.
├── config.py
├── domain #(1)
│ ├── __init__.py
│ └── model.py
├── service_layer #(2)
│ ├── __init__.py
│ └── services.py
├── adapters #(3)
│ ├── __init__.py
│ ├── orm.py
│ └── repository.py
├── entrypoints (4)
│ ├── __init__.py
│ └── flask_app.py
└── tests
├── __init__.py
├── conftest.py
├── unit
│ ├── test_allocate.py
│ ├── test_batches.py
│ └── test_services.py
├── integration
│ ├── test_orm.py
│ └── test_repository.py
└── e2e
└── test_api.py-
Let’s have a folder for our domain model. Currently that’s just one file, but for a more complex application, you might have one file per class; you might have helper parent classes for
Entity,ValueObject, andAggregate, and you might add an exceptions.py for domain-layer exceptions and, as you’ll see in [part2], commands.py and events.py. -
We’ll distinguish the service layer. Currently that’s just one file called services.py for our service-layer functions. You could add service-layer exceptions here, and as you’ll see in [chapter_05_high_gear_low_gear], we’ll add unit_of_work.py.
-
Adapters is a nod to the ports and adapters terminology. This will fill up with any other abstractions around external I/O (e.g., a redis_client.py). Strictly speaking, you would call these secondary adapters or driven adapters, or sometimes inward-facing adapters.
-
Entrypoints are the places we drive our application from. In the official ports and adapters terminology, these are adapters too, and are referred to as primary, driving, or outward-facing adapters.
What about ports? As you may remember, they are the abstract interfaces that the adapters implement. We tend to keep them in the same file as the adapters that implement them.
Wrap-Up
Adding the service layer has really bought us quite a lot:
-
Our Flask API endpoints become very thin and easy to write: their only responsibility is doing "web stuff," such as parsing JSON and producing the right HTTP codes for happy or unhappy cases.
-
We’ve defined a clear API for our domain, a set of use cases or entrypoints that can be used by any adapter without needing to know anything about our domain model classes—whether that’s an API, a CLI (see [appendix_csvs]), or the tests! They’re an adapter for our domain too.
-
We can write tests in "high gear" by using the service layer, leaving us free to refactor the domain model in any way we see fit. As long as we can still deliver the same use cases, we can experiment with new designs without needing to rewrite a load of tests.
-
And our test pyramid is looking good—the bulk of our tests are fast unit tests, with just the bare minimum of E2E and integration tests.
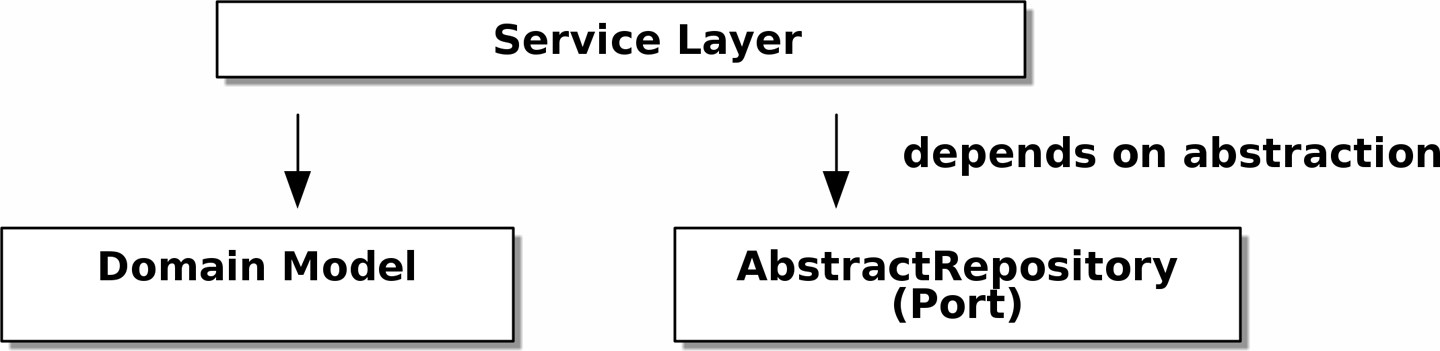
The DIP in Action
Abstract dependencies of the service layer shows the
dependencies of our service layer: the domain model
and AbstractRepository (the port, in ports and adapters terminology).
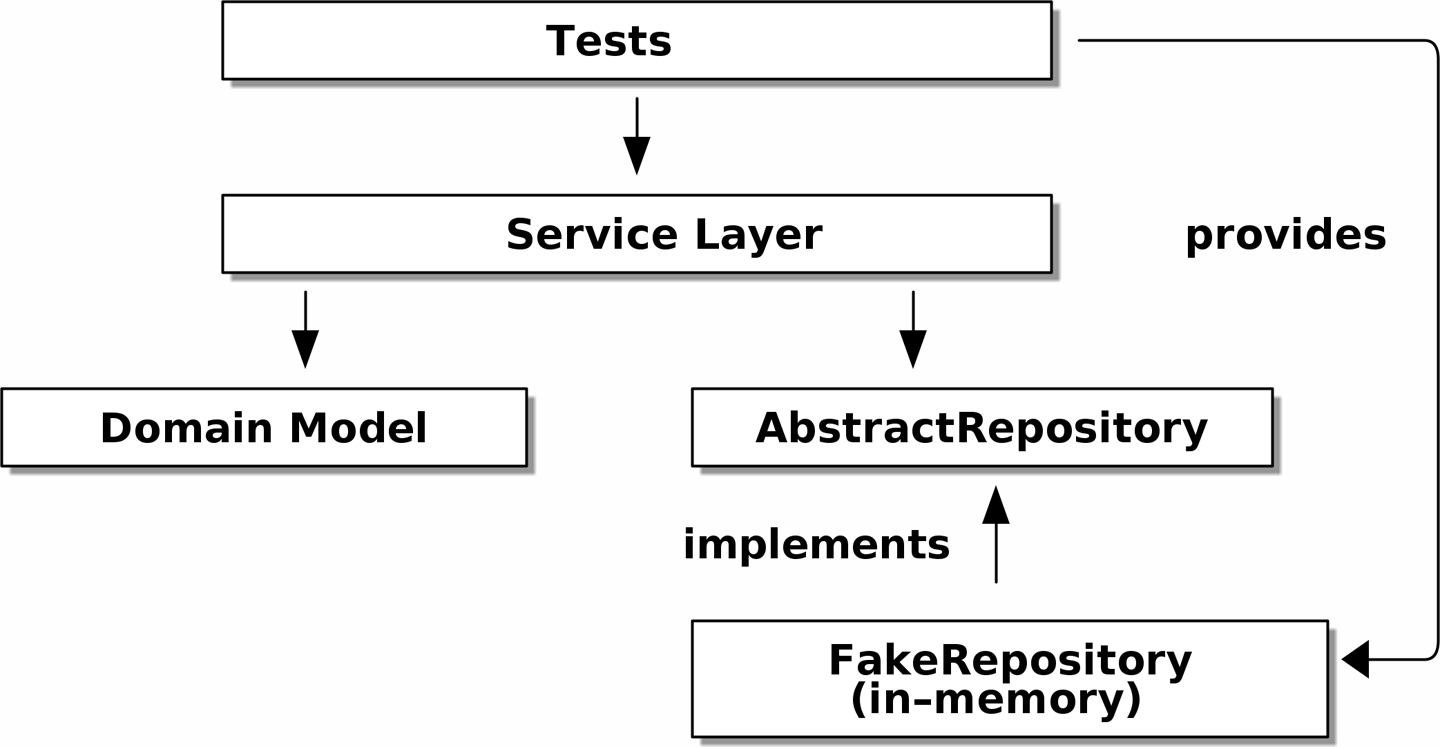
When we run the tests, Tests provide an implementation of the abstract dependency shows
how we implement the abstract dependencies by using FakeRepository (the
adapter).
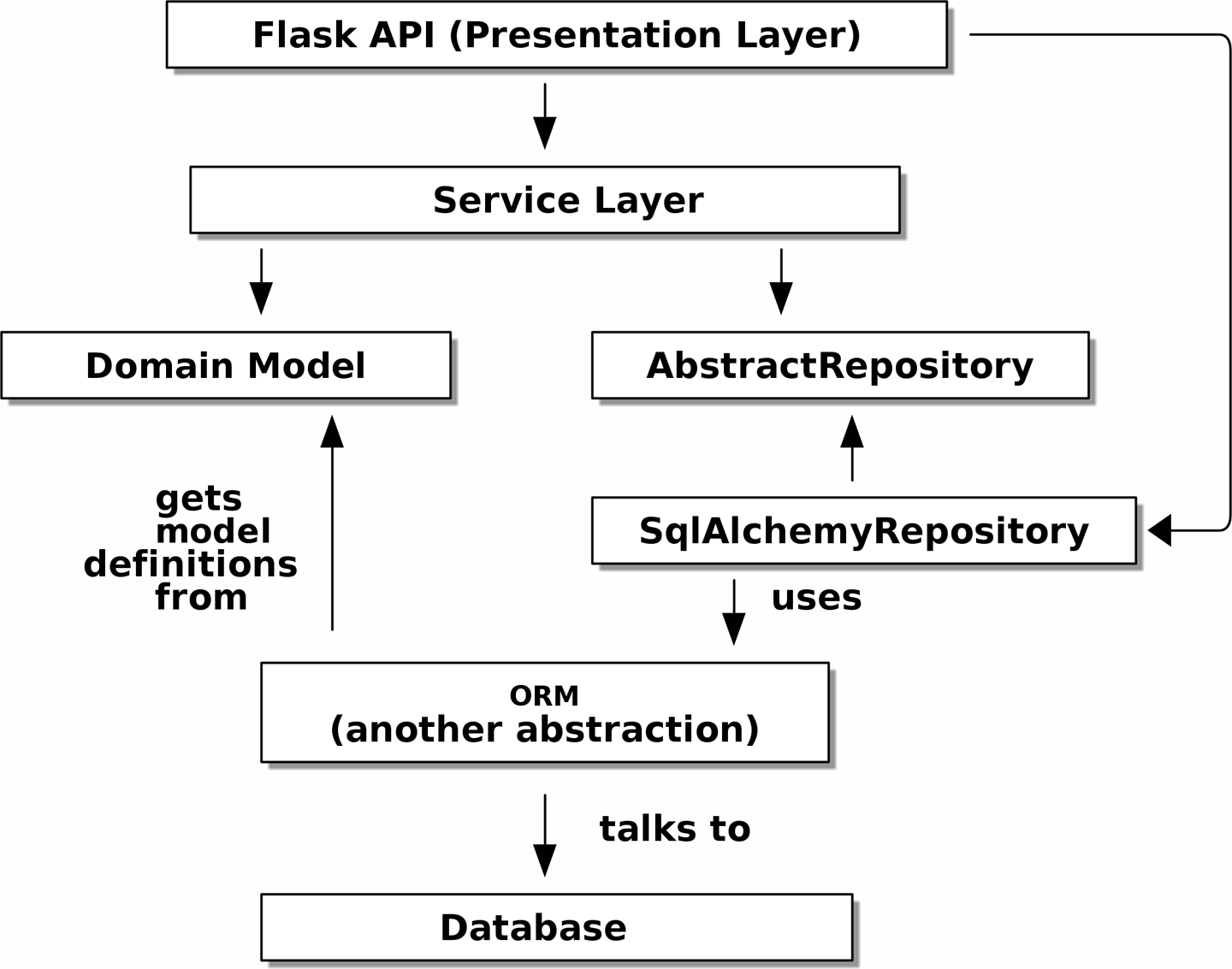
And when we actually run our app, we swap in the "real" dependency shown in Dependencies at runtime.
[ditaa, apwp_0403]
+-----------------------------+
| Service Layer |
+-----------------------------+
| |
| | depends on abstraction
V V
+------------------+ +--------------------+
| Domain Model | | AbstractRepository |
| | | (Port) |
+------------------+ +--------------------+
[ditaa, apwp_0404]
+-----------------------------+
| Tests |-------------\
+-----------------------------+ |
| |
V |
+-----------------------------+ |
| Service Layer | provides |
+-----------------------------+ |
| | |
V V |
+------------------+ +--------------------+ |
| Domain Model | | AbstractRepository | |
+------------------+ +--------------------+ |
^ |
implements | |
| |
+----------------------+ |
| FakeRepository |<--/
| (in–memory) |
+----------------------+
[ditaa, apwp_0405]
+--------------------------------+
| Flask API (Presentation Layer) |-----------\
+--------------------------------+ |
| |
V |
+-----------------------------+ |
| Service Layer | |
+-----------------------------+ |
| | |
V V |
+------------------+ +--------------------+ |
| Domain Model | | AbstractRepository | |
+------------------+ +--------------------+ |
^ ^ |
| | |
gets | +----------------------+ |
model | | SqlAlchemyRepository |<--/
definitions| +----------------------+
from | | uses
| V
+-----------------------+
| ORM |
| (another abstraction) |
+-----------------------+
|
| talks to
V
+------------------------+
| Database |
+------------------------+
Wonderful.
Let’s pause for Service layer: the trade-offs, in which we consider the pros and cons of having a service layer at all.
| Pros | Cons |
|---|---|
|
|
But there are still some bits of awkwardness to tidy up:
-
The service layer is still tightly coupled to the domain, because its API is expressed in terms of
OrderLineobjects. In [chapter_05_high_gear_low_gear], we’ll fix that and talk about the way that the service layer enables more productive TDD. -
The service layer is tightly coupled to a
sessionobject. In [chapter_06_uow], we’ll introduce one more pattern that works closely with the Repository and Service Layer patterns, the Unit of Work pattern, and everything will be absolutely lovely. You’ll see!