
6: Unit of Work Pattern
In this chapter we’ll introduce the final piece of the puzzle that ties together the Repository and Service Layer patterns: the Unit of Work pattern.
If the Repository pattern is our abstraction over the idea of persistent storage, the Unit of Work (UoW) pattern is our abstraction over the idea of atomic operations. It will allow us to finally and fully decouple our service layer from the data layer.
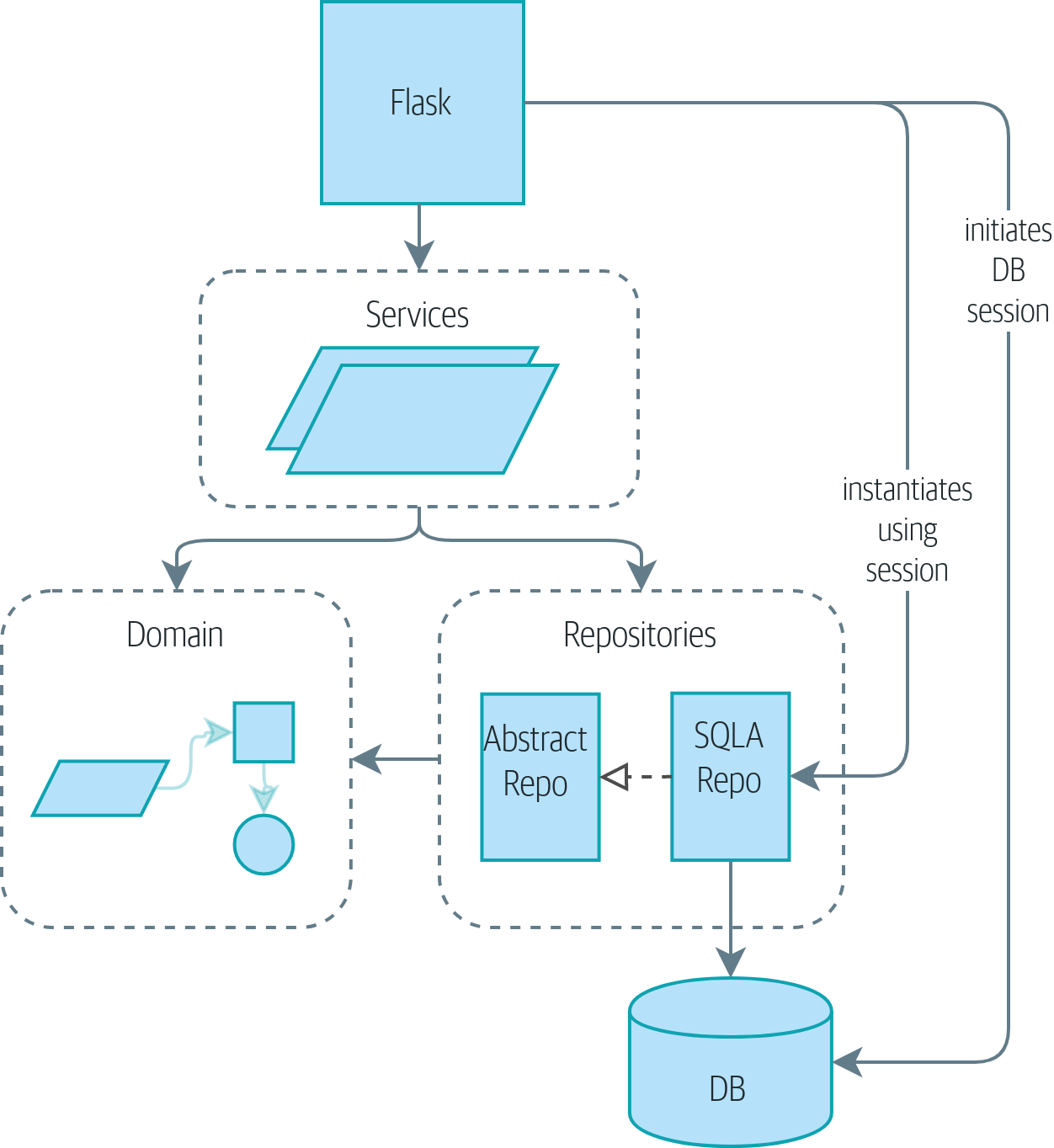
Without UoW: API talks directly to three layers shows that, currently, a lot of communication occurs
across the layers of our infrastructure: the API talks directly to the database
layer to start a session, it talks to the repository layer to initialize
SQLAlchemyRepository, and it talks to the service layer to ask it to allocate.
|
Tip
|
The code for this chapter is in the chapter_06_uow branch on GitHub: git clone https://github.com/cosmicpython/code.git cd code git checkout chapter_06_uow # or to code along, checkout Chapter 4: git checkout chapter_04_service_layer |
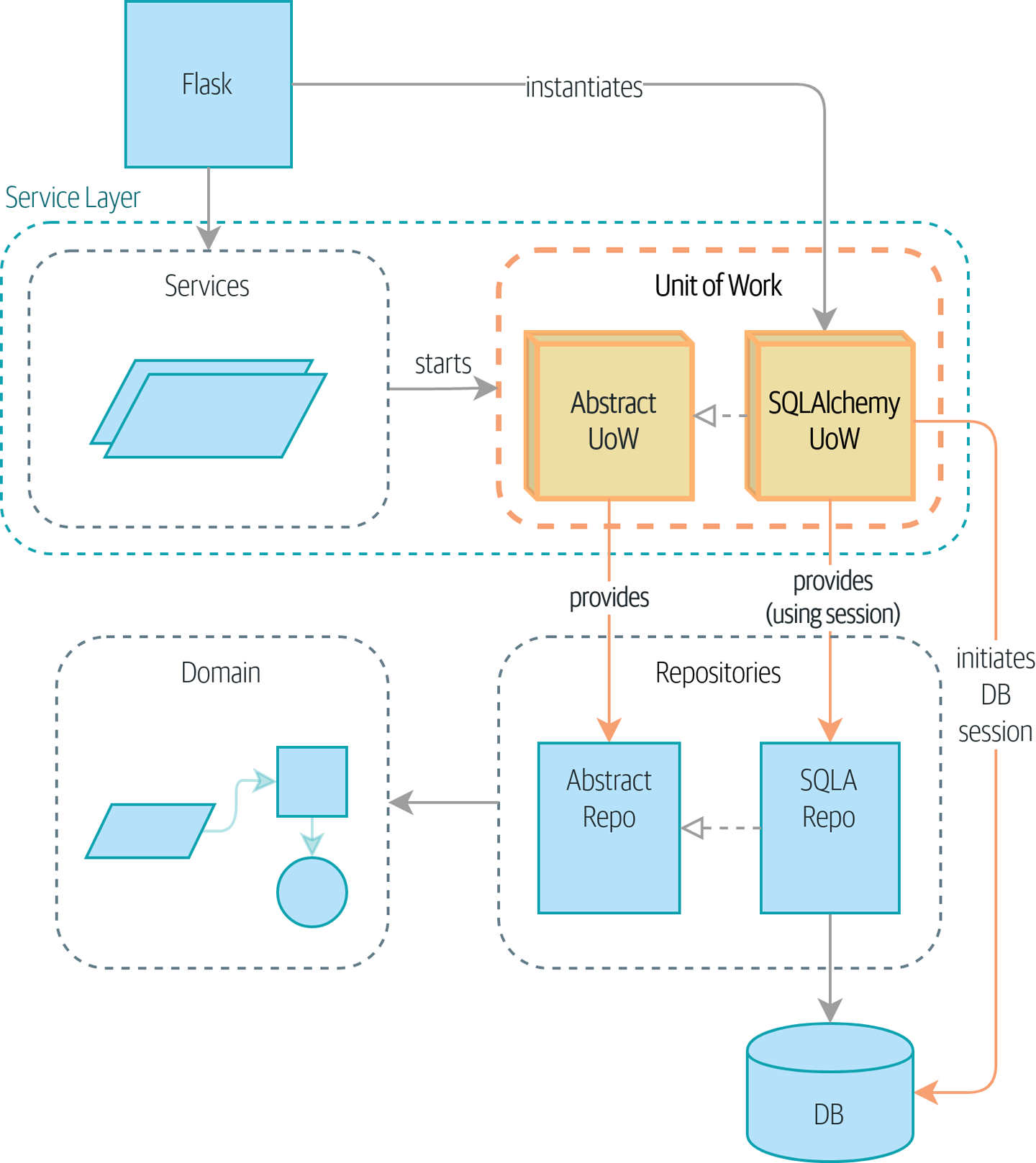
With UoW: UoW now manages database state shows our target state. The Flask API now does only two things: it initializes a unit of work, and it invokes a service. The service collaborates with the UoW (we like to think of the UoW as being part of the service layer), but neither the service function itself nor Flask now needs to talk directly to the database.
And we’ll do it all using a lovely piece of Python syntax, a context manager.
The Unit of Work Collaborates with the Repository
Let’s see the unit of work (or UoW, which we pronounce "you-wow") in action. Here’s how the service layer will look when we’re finished:
def allocate(
orderid: str, sku: str, qty: int,
uow: unit_of_work.AbstractUnitOfWork,
) -> str:
line = OrderLine(orderid, sku, qty)
with uow: #(1)
batches = uow.batches.list() #(2)
...
batchref = model.allocate(line, batches)
uow.commit() #(3)-
We’ll start a UoW as a context manager.
-
uow.batchesis the batches repo, so the UoW provides us access to our permanent storage. -
When we’re done, we commit or roll back our work, using the UoW.
The UoW acts as a single entrypoint to our persistent storage, and it keeps track of what objects were loaded and of the latest state.[1]
This gives us three useful things:
-
A stable snapshot of the database to work with, so the objects we use aren’t changing halfway through an operation
-
A way to persist all of our changes at once, so if something goes wrong, we don’t end up in an inconsistent state
-
A simple API to our persistence concerns and a handy place to get a repository
Test-Driving a UoW with Integration Tests
Here are our integration tests for the UOW:
def test_uow_can_retrieve_a_batch_and_allocate_to_it(session_factory):
session = session_factory()
insert_batch(session, "batch1", "HIPSTER-WORKBENCH", 100, None)
session.commit()
uow = unit_of_work.SqlAlchemyUnitOfWork(session_factory) #(1)
with uow:
batch = uow.batches.get(reference="batch1") #(2)
line = model.OrderLine("o1", "HIPSTER-WORKBENCH", 10)
batch.allocate(line)
uow.commit() #(3)
batchref = get_allocated_batch_ref(session, "o1", "HIPSTER-WORKBENCH")
assert batchref == "batch1"-
We initialize the UoW by using our custom session factory and get back a
uowobject to use in ourwithblock. -
The UoW gives us access to the batches repository via
uow.batches. -
We call
commit()on it when we’re done.
For the curious, the insert_batch and get_allocated_batch_ref helpers look
like this:
def insert_batch(session, ref, sku, qty, eta):
session.execute(
"INSERT INTO batches (reference, sku, _purchased_quantity, eta)"
" VALUES (:ref, :sku, :qty, :eta)",
dict(ref=ref, sku=sku, qty=qty, eta=eta),
)
def get_allocated_batch_ref(session, orderid, sku):
[[orderlineid]] = session.execute( #(1)
"SELECT id FROM order_lines WHERE orderid=:orderid AND sku=:sku",
dict(orderid=orderid, sku=sku),
)
[[batchref]] = session.execute( #(1)
"SELECT b.reference FROM allocations JOIN batches AS b ON batch_id = b.id"
" WHERE orderline_id=:orderlineid",
dict(orderlineid=orderlineid),
)
return batchref-
The
=syntax is a little too-clever-by-half, apologies. What’s happening is thatsession.executereturns a list of rows, where each row is a tuple of column values; in our specific case, it’s a list of one row, which is a tuple with one column value in. The double-square-bracket on the left hand side is doing (double) assignment-unpacking to get the single value back out of these two nested sequences. It becomes readable once you’ve used it a few times!
Unit of Work and Its Context Manager
In our tests we’ve implicitly defined an interface for what a UoW needs to do. Let’s make that explicit by using an abstract base class:
class AbstractUnitOfWork(abc.ABC):
batches: repository.AbstractRepository #(1)
def __exit__(self, *args): #(2)
self.rollback() #(4)
@abc.abstractmethod
def commit(self): #(3)
raise NotImplementedError
@abc.abstractmethod
def rollback(self): #(4)
raise NotImplementedError-
The UoW provides an attribute called
.batches, which will give us access to the batches repository. -
If you’ve never seen a context manager,
__enter__and__exit__are the two magic methods that execute when we enter thewithblock and when we exit it, respectively. They’re our setup and teardown phases. -
We’ll call this method to explicitly commit our work when we’re ready.
-
If we don’t commit, or if we exit the context manager by raising an error, we do a
rollback. (The rollback has no effect ifcommit()has been called. Read on for more discussion of this.)
The Real Unit of Work Uses SQLAlchemy Sessions
The main thing that our concrete implementation adds is the database session:
DEFAULT_SESSION_FACTORY = sessionmaker( #(1)
bind=create_engine(
config.get_postgres_uri(),
)
)
class SqlAlchemyUnitOfWork(AbstractUnitOfWork):
def __init__(self, session_factory=DEFAULT_SESSION_FACTORY):
self.session_factory = session_factory #(1)
def __enter__(self):
self.session = self.session_factory() # type: Session #(2)
self.batches = repository.SqlAlchemyRepository(self.session) #(2)
return super().__enter__()
def __exit__(self, *args):
super().__exit__(*args)
self.session.close() #(3)
def commit(self): #(4)
self.session.commit()
def rollback(self): #(4)
self.session.rollback()-
The module defines a default session factory that will connect to Postgres, but we allow that to be overridden in our integration tests so that we can use SQLite instead.
-
The
__enter__method is responsible for starting a database session and instantiating a real repository that can use that session. -
We close the session on exit.
-
Finally, we provide concrete
commit()androllback()methods that use our database session.
Fake Unit of Work for Testing
Here’s how we use a fake UoW in our service-layer tests:
class FakeUnitOfWork(unit_of_work.AbstractUnitOfWork):
def __init__(self):
self.batches = FakeRepository([]) #(1)
self.committed = False #(2)
def commit(self):
self.committed = True #(2)
def rollback(self):
pass
def test_add_batch():
uow = FakeUnitOfWork() #(3)
services.add_batch("b1", "CRUNCHY-ARMCHAIR", 100, None, uow) #(3)
assert uow.batches.get("b1") is not None
assert uow.committed
def test_allocate_returns_allocation():
uow = FakeUnitOfWork() #(3)
services.add_batch("batch1", "COMPLICATED-LAMP", 100, None, uow) #(3)
result = services.allocate("o1", "COMPLICATED-LAMP", 10, uow) #(3)
assert result == "batch1"
...-
FakeUnitOfWorkandFakeRepositoryare tightly coupled, just like the realUnitofWorkandRepositoryclasses. That’s fine because we recognize that the objects are collaborators. -
Notice the similarity with the fake
commit()function fromFakeSession(which we can now get rid of). But it’s a substantial improvement because we’re now faking out code that we wrote rather than third-party code. Some people say, "Don’t mock what you don’t own". -
In our tests, we can instantiate a UoW and pass it to our service layer, rather than passing a repository and a session. This is considerably less cumbersome.
Using the UoW in the Service Layer
Here’s what our new service layer looks like:
def add_batch(
ref: str, sku: str, qty: int, eta: Optional[date],
uow: unit_of_work.AbstractUnitOfWork, #(1)
):
with uow:
uow.batches.add(model.Batch(ref, sku, qty, eta))
uow.commit()
def allocate(
orderid: str, sku: str, qty: int,
uow: unit_of_work.AbstractUnitOfWork, #(1)
) -> str:
line = OrderLine(orderid, sku, qty)
with uow:
batches = uow.batches.list()
if not is_valid_sku(line.sku, batches):
raise InvalidSku(f"Invalid sku {line.sku}")
batchref = model.allocate(line, batches)
uow.commit()
return batchref-
Our service layer now has only the one dependency, once again on an abstract UoW.
Explicit Tests for Commit/Rollback Behavior
To convince ourselves that the commit/rollback behavior works, we wrote a couple of tests:
def test_rolls_back_uncommitted_work_by_default(session_factory):
uow = unit_of_work.SqlAlchemyUnitOfWork(session_factory)
with uow:
insert_batch(uow.session, "batch1", "MEDIUM-PLINTH", 100, None)
new_session = session_factory()
rows = list(new_session.execute('SELECT * FROM "batches"'))
assert rows == []
def test_rolls_back_on_error(session_factory):
class MyException(Exception):
pass
uow = unit_of_work.SqlAlchemyUnitOfWork(session_factory)
with pytest.raises(MyException):
with uow:
insert_batch(uow.session, "batch1", "LARGE-FORK", 100, None)
raise MyException()
new_session = session_factory()
rows = list(new_session.execute('SELECT * FROM "batches"'))
assert rows == []|
Tip
|
We haven’t shown it here, but it can be worth testing some of the more "obscure" database behavior, like transactions, against the "real" database—that is, the same engine. For now, we’re getting away with using SQLite instead of Postgres, but in [chapter_07_aggregate], we’ll switch some of the tests to using the real database. It’s convenient that our UoW class makes that easy! |
Explicit Versus Implicit Commits
Now we briefly digress on different ways of implementing the UoW pattern.
We could imagine a slightly different version of the UoW that commits by default and rolls back only if it spots an exception:
class AbstractUnitOfWork(abc.ABC):
def __enter__(self):
return self
def __exit__(self, exn_type, exn_value, traceback):
if exn_type is None:
self.commit() #(1)
else:
self.rollback() #(2)-
Should we have an implicit commit in the happy path?
-
And roll back only on exception?
It would allow us to save a line of code and to remove the explicit commit from our client code:
def add_batch(ref: str, sku: str, qty: int, eta: Optional[date], uow):
with uow:
uow.batches.add(model.Batch(ref, sku, qty, eta))
# uow.commit()This is a judgment call, but we tend to prefer requiring the explicit commit so that we have to choose when to flush state.
Although we use an extra line of code, this makes the software safe by default. The default behavior is to not change anything. In turn, that makes our code easier to reason about because there’s only one code path that leads to changes in the system: total success and an explicit commit. Any other code path, any exception, any early exit from the UoW’s scope leads to a safe state.
Similarly, we prefer to roll back by default because it’s easier to understand; this rolls back to the last commit, so either the user did one, or we blow their changes away. Harsh but simple.
Examples: Using UoW to Group Multiple Operations into an Atomic Unit
Here are a few examples showing the Unit of Work pattern in use. You can see how it leads to simple reasoning about what blocks of code happen together.
Example 1: Reallocate
Suppose we want to be able to deallocate and then reallocate orders:
def reallocate(
line: OrderLine,
uow: AbstractUnitOfWork,
) -> str:
with uow:
batch = uow.batches.get(sku=line.sku)
if batch is None:
raise InvalidSku(f'Invalid sku {line.sku}')
batch.deallocate(line) #(1)
allocate(line) #(2)
uow.commit()-
If
deallocate()fails, we don’t want to callallocate(), obviously. -
If
allocate()fails, we probably don’t want to actually commit thedeallocate()either.
Example 2: Change Batch Quantity
Our shipping company gives us a call to say that one of the container doors opened, and half our sofas have fallen into the Indian Ocean. Oops!
def change_batch_quantity(
batchref: str, new_qty: int,
uow: AbstractUnitOfWork,
):
with uow:
batch = uow.batches.get(reference=batchref)
batch.change_purchased_quantity(new_qty)
while batch.available_quantity < 0:
line = batch.deallocate_one() #(1)
uow.commit()-
Here we may need to deallocate any number of lines. If we get a failure at any stage, we probably want to commit none of the changes.
Tidying Up the Integration Tests
We now have three sets of tests, all essentially pointing at the database: test_orm.py, test_repository.py, and test_uow.py. Should we throw any away?
└── tests
├── conftest.py
├── e2e
│ └── test_api.py
├── integration
│ ├── test_orm.py
│ ├── test_repository.py
│ └── test_uow.py
├── pytest.ini
└── unit
├── test_allocate.py
├── test_batches.py
└── test_services.pyYou should always feel free to throw away tests if you think they’re not going to add value longer term. We’d say that test_orm.py was primarily a tool to help us learn SQLAlchemy, so we won’t need that long term, especially if the main things it’s doing are covered in test_repository.py. That last test, you might keep around, but we could certainly see an argument for just keeping everything at the highest possible level of abstraction (just as we did for the unit tests).
|
Tip
|
This is another example of the lesson from [chapter_05_high_gear_low_gear]: as we build better abstractions, we can move our tests to run against them, which leaves us free to change the underlying details. |
Wrap-Up
Hopefully we’ve convinced you that the Unit of Work pattern is useful, and that the context manager is a really nice Pythonic way of visually grouping code into blocks that we want to happen atomically.
This pattern is so useful, in fact, that SQLAlchemy already uses a UoW
in the shape of the Session object. The Session object in SQLAlchemy is the way
that your application loads data from the database.
Every time you load a new entity from the database, the session begins to track changes to the entity, and when the session is flushed, all your changes are persisted together. Why do we go to the effort of abstracting away the SQLAlchemy session if it already implements the pattern we want?
Unit of Work pattern: the trade-offs discusses some of the trade-offs.
| Pros | Cons |
|---|---|
|
|
For one thing, the Session API is rich and supports operations that we don’t
want or need in our domain. Our UnitOfWork simplifies the session to its
essential core: it can be started, committed, or thrown away.
For another, we’re using the UnitOfWork to access our Repository objects.
This is a neat bit of developer usability that we couldn’t do with a plain
SQLAlchemy Session.
Lastly, we’re motivated again by the dependency inversion principle: our service layer depends on a thin abstraction, and we attach a concrete implementation at the outside edge of the system. This lines up nicely with SQLAlchemy’s own recommendations:
Keep the life cycle of the session (and usually the transaction) separate and external. The most comprehensive approach, recommended for more substantial applications, will try to keep the details of session, transaction, and exception management as far as possible from the details of the program doing its work.