
Epilogue: Epilogue
What Now?
Phew! We’ve covered a lot of ground in this book, and for most of our audience all of these ideas are new. With that in mind, we can’t hope to make you experts in these techniques. All we can really do is show you the broad-brush ideas, and just enough code for you to go ahead and write something from scratch.
The code we’ve shown in this book isn’t battle-hardened production code: it’s a set of Lego blocks that you can play with to make your first house, spaceship, and skyscraper.
That leaves us with two big tasks. We want to talk about how to start applying these ideas for real in an existing system, and we need to warn you about some of the things we had to skip. We’ve given you a whole new arsenal of ways to shoot yourself in the foot, so we should discuss some basic firearms safety.
How Do I Get There from Here?
Chances are that a lot of you are thinking something like this:
"OK Bob and Harry, that’s all well and good, and if I ever get hired to work on a green-field new service, I know what to do. But in the meantime, I’m here with my big ball of Django mud, and I don’t see any way to get to your nice, clean, perfect, untainted, simplistic model. Not from here."
We hear you. Once you’ve already built a big ball of mud, it’s hard to know how to start improving things. Really, we need to tackle things step by step.
First things first: what problem are you trying to solve? Is the software too hard to change? Is the performance unacceptable? Have you got weird, inexplicable bugs?
Having a clear goal in mind will help you to prioritize the work that needs to be done and, importantly, communicate the reasons for doing it to the rest of the team. Businesses tend to have pragmatic approaches to technical debt and refactoring, so long as engineers can make a reasoned argument for fixing things.
|
Tip
|
Making complex changes to a system is often an easier sell if you link it to feature work. Perhaps you’re launching a new product or opening your service to new markets? This is the right time to spend engineering resources on fixing the foundations. With a six-month project to deliver, it’s easier to make the argument for three weeks of cleanup work. Bob refers to this as architecture tax. |
Separating Entangled Responsibilities
At the beginning of the book, we said that the main characteristic of a big ball of mud is homogeneity: every part of the system looks the same, because we haven’t been clear about the responsibilities of each component. To fix that, we’ll need to start separating out responsibilities and introducing clear boundaries. One of the first things we can do is to start building a service layer (Domain of a collaboration system).
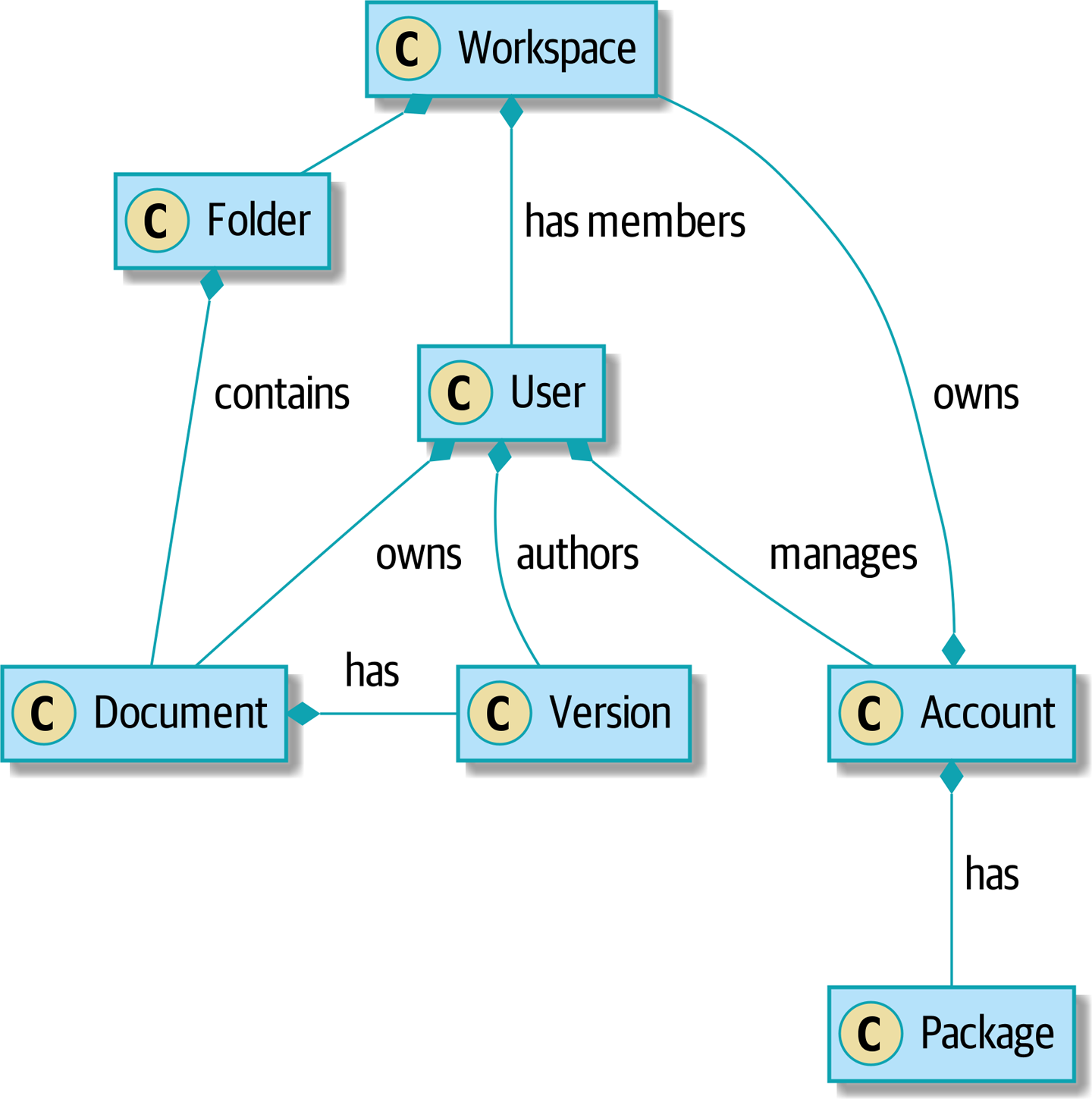
[plantuml, apwp_ep01, config=plantuml.cfg] @startuml scale 4 hide empty members Workspace *- Folder : contains Account *- Workspace : owns Account *-- Package : has User *-- Account : manages Workspace *-- User : has members User *-- Document : owns Folder *-- Document : contains Document *- Version: has User *-- Version: authors @enduml
This was the system in which Bob first learned how to break apart a ball of mud, and it was a doozy. There was logic everywhere—in the web pages, in manager objects, in helpers, in fat service classes that we’d written to abstract the managers and helpers, and in hairy command objects that we’d written to break apart the services.
If you’re working in a system that’s reached this point, the situation can feel hopeless, but it’s never too late to start weeding an overgrown garden. Eventually, we hired an architect who knew what he was doing, and he helped us get things back under control.
Start by working out the use cases of your system. If you have a user interface, what actions does it perform? If you have a backend processing component, maybe each cron job or Celery job is a single use case. Each of your use cases needs to have an imperative name: Apply Billing Charges, Clean Abandoned Accounts, or Raise Purchase Order, for example.
In our case, most of our use cases were part of the manager classes and had names like Create Workspace or Delete Document Version. Each use case was invoked from a web frontend.
We aim to create a single function or class for each of these supported operations that deals with orchestrating the work to be done. Each use case should do the following:
-
Start its own database transaction if needed
-
Fetch any required data
-
Check any preconditions (see the Ensure pattern in [appendix_validation])
-
Update the domain model
-
Persist any changes
Each use case should succeed or fail as an atomic unit. You might need to call one use case from another. That’s OK; just make a note of it, and try to avoid long-running database transactions.
|
Note
|
One of the biggest problems we had was that manager methods called other manager methods, and data access could happen from the model objects themselves. It was hard to understand what each operation did without going on a treasure hunt across the codebase. Pulling all the logic into a single method, and using a UoW to control our transactions, made the system easier to reason about. |
|
Tip
|
It’s fine if you have duplication in the use-case functions. We’re not trying to write perfect code; we’re just trying to extract some meaningful layers. It’s better to duplicate some code in a few places than to have use-case functions calling one another in a long chain. |
This is a good opportunity to pull any data-access or orchestration code out of the domain model and into the use cases. We should also try to pull I/O concerns (e.g., sending email, writing files) out of the domain model and up into the use-case functions. We apply the techniques from [chapter_03_abstractions] on abstractions to keep our handlers unit testable even when they’re performing I/O.
These use-case functions will mostly be about logging, data access, and error handling. Once you’ve done this step, you’ll have a grasp of what your program actually does, and a way to make sure each operation has a clearly defined start and finish. We’ll have taken a step toward building a pure domain model.
Read Working Effectively with Legacy Code by Michael C. Feathers (Prentice Hall) for guidance on getting legacy code under test and starting separating responsibilities.
Identifying Aggregates and Bounded Contexts
Part of the problem with the codebase in our case study was that the object graph was highly connected. Each account had many workspaces, and each workspace had many members, all of whom had their own accounts. Each workspace contained many documents, which had many versions.
You can’t express the full horror of the thing in a class diagram. For one thing, there wasn’t really a single account related to a user. Instead, there was a bizarre rule requiring you to enumerate all of the accounts associated to the user via the workspaces and take the one with the earliest creation date.
Every object in the system was part of an inheritance hierarchy that included
SecureObject and Version. This inheritance hierarchy was mirrored directly
in the database schema, so that every query had to join across 10 different
tables and look at a discriminator column just to tell what kind of objects
you were working with.
The codebase made it easy to "dot" your way through these objects like so:
user.account.workspaces[0].documents.versions[1].owner.account.settings[0];Building a system this way with Django ORM or SQLAlchemy is easy but is to be avoided. Although it’s convenient, it makes it very hard to reason about performance because each property might trigger a lookup to the database.
|
Tip
|
Aggregates are a consistency boundary. In general, each use case should update a single aggregate at a time. One handler fetches one aggregate from a repository, modifies its state, and raises any events that happen as a result. If you need data from another part of the system, it’s totally fine to use a read model, but avoid updating multiple aggregates in a single transaction. When we choose to separate code into different aggregates, we’re explicitly choosing to make them eventually consistent with one another. |
A bunch of operations required us to loop over objects this way—for example:
# Lock a user's workspaces for nonpayment
def lock_account(user):
for workspace in user.account.workspaces:
workspace.archive()Or even recurse over collections of folders and documents:
def lock_documents_in_folder(folder):
for doc in folder.documents:
doc.archive()
for child in folder.children:
lock_documents_in_folder(child)These operations killed performance, but fixing them meant giving up our single object graph. Instead, we began to identify aggregates and to break the direct links between objects.
|
Note
|
We talked about the infamous SELECT N+1 problem in [chapter_12_cqrs], and how
we might choose to use different techniques when reading data for queries versus
reading data for commands.
|
Mostly we did this by replacing direct references with identifiers.
Before aggregates:
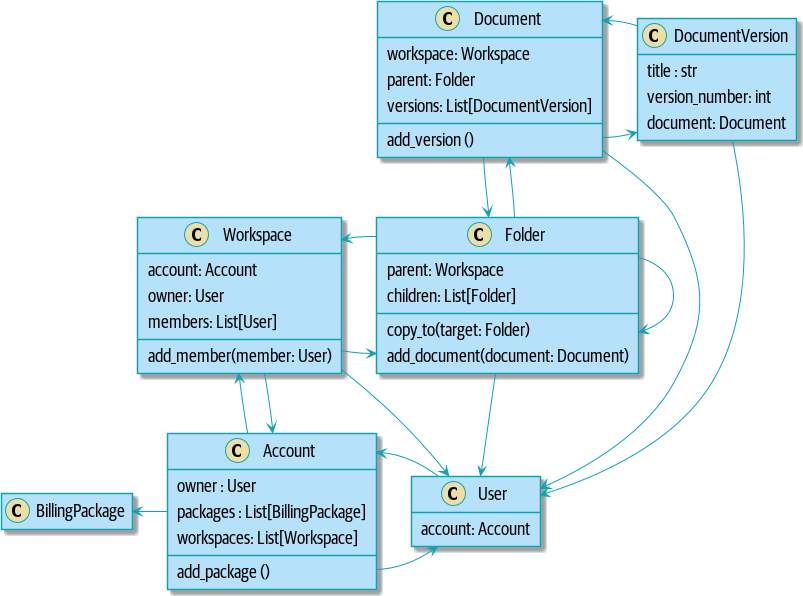
[plantuml, apwp_ep02, config=plantuml.cfg]
@startuml
scale 4
hide empty members
together {
class Document {
add_version()
workspace: Workspace
parent: Folder
versions: List[DocumentVersion]
}
class DocumentVersion {
title : str
version_number: int
document: Document
}
class Folder {
parent: Workspace
children: List[Folder]
copy_to(target: Folder)
add_document(document: Document)
}
}
together {
class User {
account: Account
}
class Account {
add_package()
owner : User
packages : List[BillingPackage]
workspaces: List[Workspace]
}
}
class BillingPackage {
}
class Workspace {
add_member(member: User)
account: Account
owner: User
members: List[User]
}
Account --> Workspace
Account -left-> BillingPackage
Account -right-> User
Workspace --> User
Workspace --> Folder
Workspace --> Account
Folder --> Folder
Folder --> Document
Folder --> Workspace
Folder --> User
Document -right-> DocumentVersion
Document --> Folder
Document --> User
DocumentVersion -right-> Document
DocumentVersion --> User
User -left-> Account
@enduml
After modeling with aggregates:
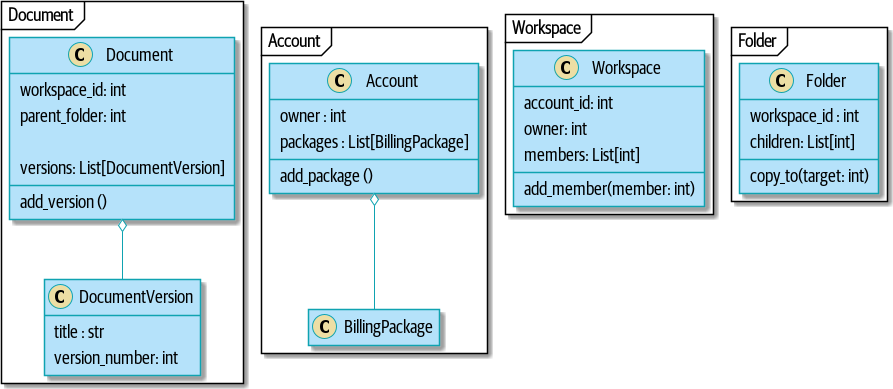
[plantuml, apwp_ep03, config=plantuml.cfg]
@startuml
scale 4
hide empty members
frame Document {
class Document {
add_version()
workspace_id: int
parent_folder: int
versions: List[DocumentVersion]
}
class DocumentVersion {
title : str
version_number: int
}
}
frame Account {
class Account {
add_package()
owner : int
packages : List[BillingPackage]
}
class BillingPackage {
}
}
frame Workspace {
class Workspace {
add_member(member: int)
account_id: int
owner: int
members: List[int]
}
}
frame Folder {
class Folder {
workspace_id : int
children: List[int]
copy_to(target: int)
}
}
Document o-- DocumentVersion
Account o-- BillingPackage
@enduml
|
Tip
|
Bidirectional links are often a sign that your aggregates aren’t right.
In our original code, a Document knew about its containing Folder, and the
Folder had a collection of Documents. This makes it easy to traverse the
object graph but stops us from thinking properly about the consistency
boundaries we need. We break apart aggregates by using references instead.
In the new model, a Document had reference to its parent_folder but had no way
to directly access the Folder.
|
If we needed to read data, we avoided writing complex loops and transforms and tried to replace them with straight SQL. For example, one of our screens was a tree view of folders and documents.
This screen was incredibly heavy on the database, because it relied on nested
for loops that triggered a lazy-loaded ORM.
|
Tip
|
We use this same technique in [chapter_12_cqrs], where we replace a nested loop over ORM objects with a simple SQL query. It’s the first step in a CQRS approach. |
After a lot of head-scratching, we replaced the ORM code with a big, ugly stored
procedure. The code looked horrible, but it was much faster and helped
to break the links between Folder and Document.
When we needed to write data, we changed a single aggregate at a time, and we
introduced a message bus to handle events. For example, in the new model, when
we locked an account, we could first query for all the affected workspaces via
SELECT id FROM workspace WHERE account_id = ?.
We could then raise a new command for each workspace:
for workspace_id in workspaces:
bus.handle(LockWorkspace(workspace_id))An Event-Driven Approach to Go to Microservices via Strangler Pattern
The Strangler Fig pattern involves creating a new system around the edges of an old system, while keeping it running. Bits of old functionality are gradually intercepted and replaced, until the old system is left doing nothing at all and can be switched off.
When building the availability service, we used a technique called event interception to move functionality from one place to another. This is a three-step process:
-
Raise events to represent the changes happening in a system you want to replace.
-
Build a second system that consumes those events and uses them to build its own domain model.
-
Replace the older system with the new.
We used event interception to move from Before: strong, bidirectional coupling based on XML-RPC…

[plantuml, apwp_ep04, config=plantuml.cfg] @startuml Ecommerce Context !include images/C4_Context.puml LAYOUT_LEFT_RIGHT scale 2 Person_Ext(customer, "Customer", "Wants to buy furniture") System(fulfillment, "Fulfillment System", "Manages order fulfillment and logistics") System(ecom, "Ecommerce website", "Allows customers to buy furniture") Rel(customer, ecom, "Uses") Rel(fulfillment, ecom, "Updates stock and orders", "xml-rpc") Rel(ecom, fulfillment, "Sends orders", "xml-rpc") @enduml
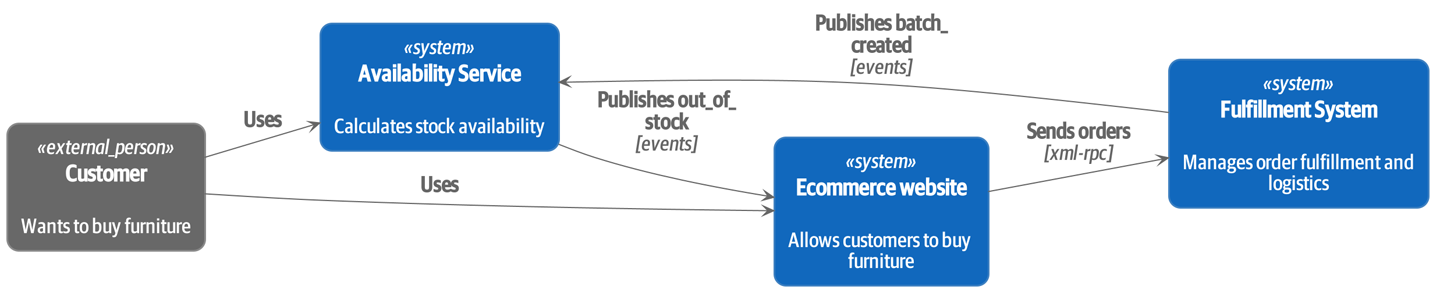
[plantuml, apwp_ep05, config=plantuml.cfg] @startuml Ecommerce Context !include images/C4_Context.puml LAYOUT_LEFT_RIGHT scale 2 Person_Ext(customer, "Customer", "Wants to buy furniture") System(av, "Availability Service", "Calculates stock availability") System(fulfillment, "Fulfillment System", "Manages order fulfillment and logistics") System(ecom, "Ecommerce website", "Allows customers to buy furniture") Rel(customer, ecom, "Uses") Rel(customer, av, "Uses") Rel(fulfillment, av, "Publishes batch_created", "events") Rel(av, ecom, "Publishes out_of_stock", "events") Rel(ecom, fulfillment, "Sends orders", "xml-rpc") @enduml
Practically, this was a several month-long project. Our first step was to write a domain model that could represent batches, shipments, and products. We used TDD to build a toy system that could answer a single question: "If I want N units of HAZARDOUS_RUG, how long will they take to be delivered?"
|
Tip
|
When deploying an event-driven system, start with a "walking skeleton." Deploying a system that just logs its input forces us to tackle all the infrastructural questions and start working in production. |
Once we had a working domain model, we switched to building out some
infrastructural pieces. Our first production deployment was a tiny system that
could receive a batch_created event and log its JSON representation. This is
the "Hello World" of event-driven architecture. It forced us to deploy a message
bus, hook up a producer and consumer, build a deployment pipeline, and write a
simple message handler.
Given a deployment pipeline, the infrastructure we needed, and a basic domain model, we were off. A couple months later, we were in production and serving real customers.
Convincing Your Stakeholders to Try Something New
If you’re thinking about carving a new system out of a big ball of mud, you’re probably suffering problems with reliability, performance, maintainability, or all three simultaneously. Deep, intractable problems call for drastic measures!
We recommend domain modeling as a first step. In many overgrown systems, the engineers, product owners, and customers no longer speak the same language. Business stakeholders speak about the system in abstract, process-focused terms, while developers are forced to speak about the system as it physically exists in its wild and chaotic state.
Figuring out how to model your domain is a complex task that’s the subject of many decent books in its own right. We like to use interactive techniques like event storming and CRC modeling, because humans are good at collaborating through play. Event modeling is another technique that brings engineers and product owners together to understand a system in terms of commands, queries, and events.
|
Tip
|
Check out www.eventmodeling.org and www.eventstorming.com for some great guides to visual modeling of systems with events. |
The goal is to be able to talk about the system by using the same ubiquitous language, so that you can agree on where the complexity lies.
We’ve found a lot of value in treating domain problems as TDD kata. For example, the first code we wrote for the availability service was the batch and order line model. You can treat this as a lunchtime workshop, or as a spike at the beginning of a project. Once you can demonstrate the value of modeling, it’s easier to make the argument for structuring the project to optimize for modeling.
Questions Our Tech Reviewers Asked That We Couldn’t Work into Prose
Here are some questions we heard during drafting that we couldn’t find a good place to address elsewhere in the book:
- Do I need to do all of this at once? Can I just do a bit at a time?
-
No, you can absolutely adopt these techniques bit by bit. If you have an existing system, we recommend building a service layer to try to keep orchestration in one place. Once you have that, it’s much easier to push logic into the model and push edge concerns like validation or error handling to the entrypoints.
It’s worth having a service layer even if you still have a big, messy Django ORM because it’s a way to start understanding the boundaries of operations.
- Extracting use cases will break a lot of my existing code; it’s too tangled
-
Just copy and paste. It’s OK to cause more duplication in the short term. Think of this as a multistep process. Your code is in a bad state now, so copy and paste it to a new place and then make that new code clean and tidy.
Once you’ve done that, you can replace uses of the old code with calls to your new code and finally delete the mess. Fixing large codebases is a messy and painful process. Don’t expect things to get instantly better, and don’t worry if some bits of your application stay messy.
- Do I need to do CQRS? That sounds weird. Can’t I just use repositories?
-
Of course you can! The techniques we’re presenting in this book are intended to make your life easier. They’re not some kind of ascetic discipline with which to punish yourself.
In the workspace/documents case-study system, we had a lot of View Builder objects that used repositories to fetch data and then performed some transformations to return dumb read models. The advantage is that when you hit a performance problem, it’s easy to rewrite a view builder to use custom queries or raw SQL.
- How should use cases interact across a larger system? Is it a problem for one to call another?
-
This might be an interim step. Again, in the documents case study, we had handlers that would need to invoke other handlers. This gets really messy, though, and it’s much better to move to using a message bus to separate these concerns.
Generally, your system will have a single message bus implementation and a bunch of subdomains that center on a particular aggregate or set of aggregates. When your use case has finished, it can raise an event, and a handler elsewhere can run.
- Is it a code smell for a use case to use multiple repositories/aggregates, and if so, why?
-
An aggregate is a consistency boundary, so if your use case needs to update two aggregates atomically (within the same transaction), then your consistency boundary is wrong, strictly speaking. Ideally you should think about moving to a new aggregate that wraps up all the things you want to change at the same time.
If you’re actually updating only one aggregate and using the other(s) for read-only access, then that’s fine, although you could consider building a read/view model to get you that data instead—it makes things cleaner if each use case has only one aggregate.
If you do need to modify two aggregates, but the two operations don’t have to be in the same transaction/UoW, then consider splitting the work out into two different handlers and using a domain event to carry information between the two. You can read more in these papers on aggregate design by Vaughn Vernon.
- What if I have a read-only but business-logic-heavy system?
-
View models can have complex logic in them. In this book, we’ve encouraged you to separate your read and write models because they have different consistency and throughput requirements. Mostly, we can use simpler logic for reads, but that’s not always true. In particular, permissions and authorization models can add a lot of complexity to our read side.
We’ve written systems in which the view models needed extensive unit tests. In those systems, we split a view builder from a view fetcher, as in A view builder and view fetcher (you can find a high-resolution version of this diagram at cosmicpython.com).
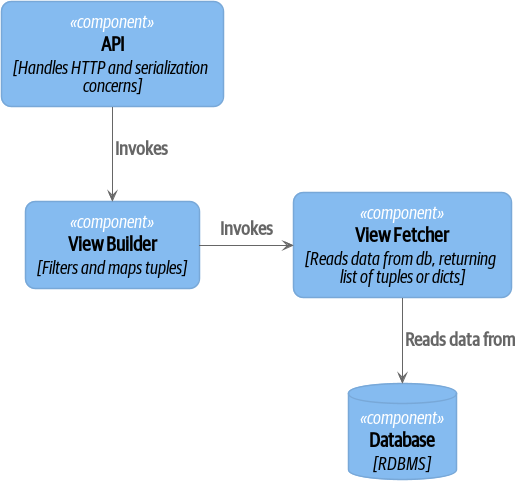
[plantuml, apwp_ep06, config=plantuml.cfg] @startuml View Fetcher Component Diagram !include images/C4_Component.puml ComponentDb(db, "Database", "RDBMS") Component(fetch, "View Fetcher", "Reads data from db, returning list of tuples or dicts") Component(build, "View Builder", "Filters and maps tuples") Component(api, "API", "Handles HTTP and serialization concerns") Rel(api, build, "Invokes") Rel_R(build, fetch, "Invokes") Rel_D(fetch, db, "Reads data from") @enduml
+ This makes it easy to test the view builder by giving it mocked data (e.g., a list of dicts). "Fancy CQRS" with event handlers is really a way of running our complex view logic whenever we write so that we can avoid running it when we read.
- Do I need to build microservices to do this stuff?
-
Egads, no! These techniques predate microservices by a decade or so. Aggregates, domain events, and dependency inversion are ways to control complexity in large systems. It just so happens that when you’ve built a set of use cases and a model for a business process, moving it to its own service is relatively easy, but that’s not a requirement.
- I’m using Django. Can I still do this?
-
We have an entire appendix just for you: [appendix_django]!
Footguns
OK, so we’ve given you a whole bunch of new toys to play with. Here’s the fine print. Harry and Bob do not recommend that you copy and paste our code into a production system and rebuild your automated trading platform on Redis pub/sub. For reasons of brevity and simplicity, we’ve hand-waved a lot of tricky subjects. Here’s a list of things we think you should know before trying this for real.
- Reliable messaging is hard
-
Redis pub/sub is not reliable and shouldn’t be used as a general-purpose messaging tool. We picked it because it’s familiar and easy to run. At MADE, we run Event Store as our messaging tool, but we’ve had experience with RabbitMQ and Amazon EventBridge.
Tyler Treat has some excellent blog posts on his site bravenewgeek.com; you should read at least read "You Cannot Have Exactly-Once Delivery" and "What You Want Is What You Don’t: Understanding Trade-Offs in Distributed Messaging".
- We explicitly choose small, focused transactions that can fail independently
-
In [chapter_08_events_and_message_bus], we update our process so that deallocating an order line and reallocating the line happen in two separate units of work. You will need monitoring to know when these transactions fail, and tooling to replay events. Some of this is made easier by using a transaction log as your message broker (e.g., Kafka or EventStore). You might also look at the Outbox pattern.
- We don’t discuss idempotency
-
We haven’t given any real thought to what happens when handlers are retried. In practice you will want to make handlers idempotent so that calling them repeatedly with the same message will not make repeated changes to state. This is a key technique for building reliability, because it enables us to safely retry events when they fail.
There’s a lot of good material on idempotent message handling, try starting with "How to Ensure Idempotency in an Eventual Consistent DDD/CQRS Application" and "(Un)Reliability in Messaging".
- Your events will need to change their schema over time
-
You’ll need to find some way of documenting your events and sharing schema with consumers. We like using JSON schema and markdown because it’s simple but there is other prior art. Greg Young wrote an entire book on managing event-driven systems over time: Versioning in an Event Sourced System (Leanpub).
More Required Reading
A few more books we’d like to recommend to help you on your way:
-
Clean Architectures in Python by Leonardo Giordani (Leanpub), which came out in 2019, is one of the few previous books on application architecture in Python.
-
Enterprise Integration Patterns by Gregor Hohpe and Bobby Woolf (Addison-Wesley Professional) is a pretty good start for messaging patterns.
-
Monolith to Microservices by Sam Newman (O’Reilly), and Newman’s first book, Building Microservices (O’Reilly). The Strangler Fig pattern is mentioned as a favorite, along with many others. These are good to check out if you’re thinking of moving to microservices, and they’re also good on integration patterns and the considerations of async messaging-based integration.
Wrap-Up
Phew! That’s a lot of warnings and reading suggestions; we hope we haven’t scared you off completely. Our goal with this book is to give you just enough knowledge and intuition for you to start building some of this for yourself. We would love to hear how you get on and what problems you’re facing with the techniques in your own systems, so why not get in touch with us over at www.cosmicpython.com?