
11: Event-Driven Architecture: Using Events to Integrate Microservices
In the preceding chapter, we never actually spoke about how we would receive the "batch quantity changed" events, or indeed, how we might notify the outside world about reallocations.
We have a microservice with a web API, but what about other ways of talking to other systems? How will we know if, say, a shipment is delayed or the quantity is amended? How will we tell the warehouse system that an order has been allocated and needs to be sent to a customer?
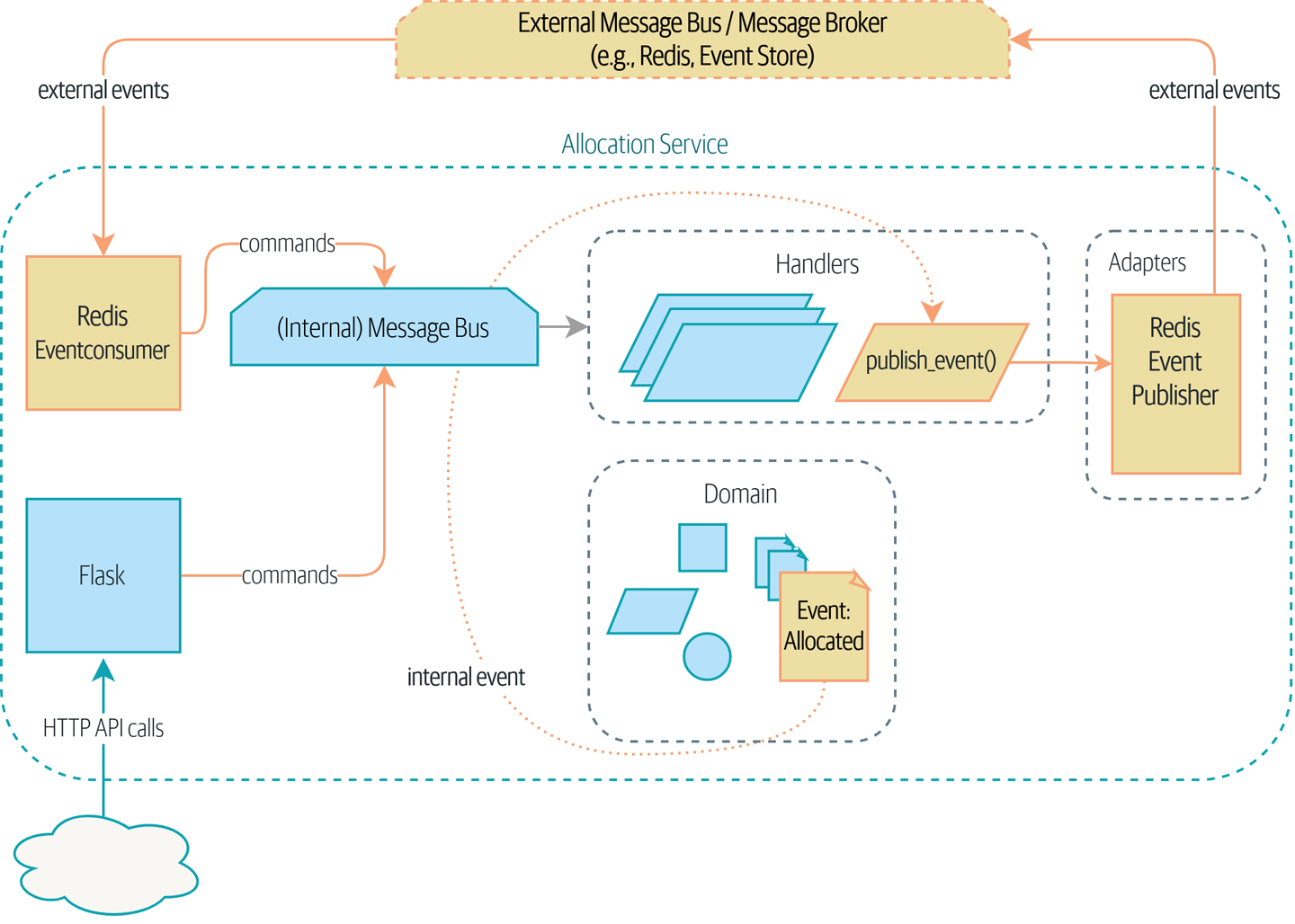
In this chapter, we’d like to show how the events metaphor can be extended to encompass the way that we handle incoming and outgoing messages from the system. Internally, the core of our application is now a message processor. Let’s follow through on that so it becomes a message processor externally as well. As shown in Our application is a message processor, our application will receive events from external sources via an external message bus (we’ll use Redis pub/sub queues as an example) and publish its outputs, in the form of events, back there as well.
|
Tip
|
The code for this chapter is in the chapter_11_external_events branch on GitHub: git clone https://github.com/cosmicpython/code.git cd code git checkout chapter_11_external_events # or to code along, checkout the previous chapter: git checkout chapter_10_commands |
Distributed Ball of Mud, and Thinking in Nouns
Before we get into that, let’s talk about the alternatives. We regularly talk to engineers who are trying to build out a microservices architecture. Often they are migrating from an existing application, and their first instinct is to split their system into nouns.
What nouns have we introduced so far in our system? Well, we have batches of stock, orders, products, and customers. So a naive attempt at breaking up the system might have looked like Context diagram with noun-based services (notice that we’ve named our system after a noun, Batches, instead of Allocation).
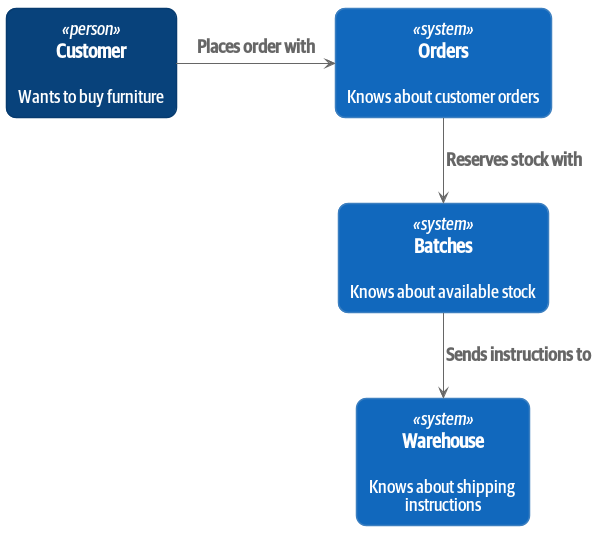
[plantuml, apwp_1102, config=plantuml.cfg] @startuml Batches Context Diagram !include images/C4_Context.puml System(batches, "Batches", "Knows about available stock") Person(customer, "Customer", "Wants to buy furniture") System(orders, "Orders", "Knows about customer orders") System(warehouse, "Warehouse", "Knows about shipping instructions") Rel_R(customer, orders, "Places order with") Rel_D(orders, batches, "Reserves stock with") Rel_D(batches, warehouse, "Sends instructions to") @enduml
Each "thing" in our system has an associated service, which exposes an HTTP API.
Let’s work through an example happy-path flow in Command flow 1: our users visit a website and can choose from products that are in stock. When they add an item to their basket, we will reserve some stock for them. When an order is complete, we confirm the reservation, which causes us to send dispatch instructions to the warehouse. Let’s also say, if this is the customer’s third order, we want to update the customer record to flag them as a VIP.
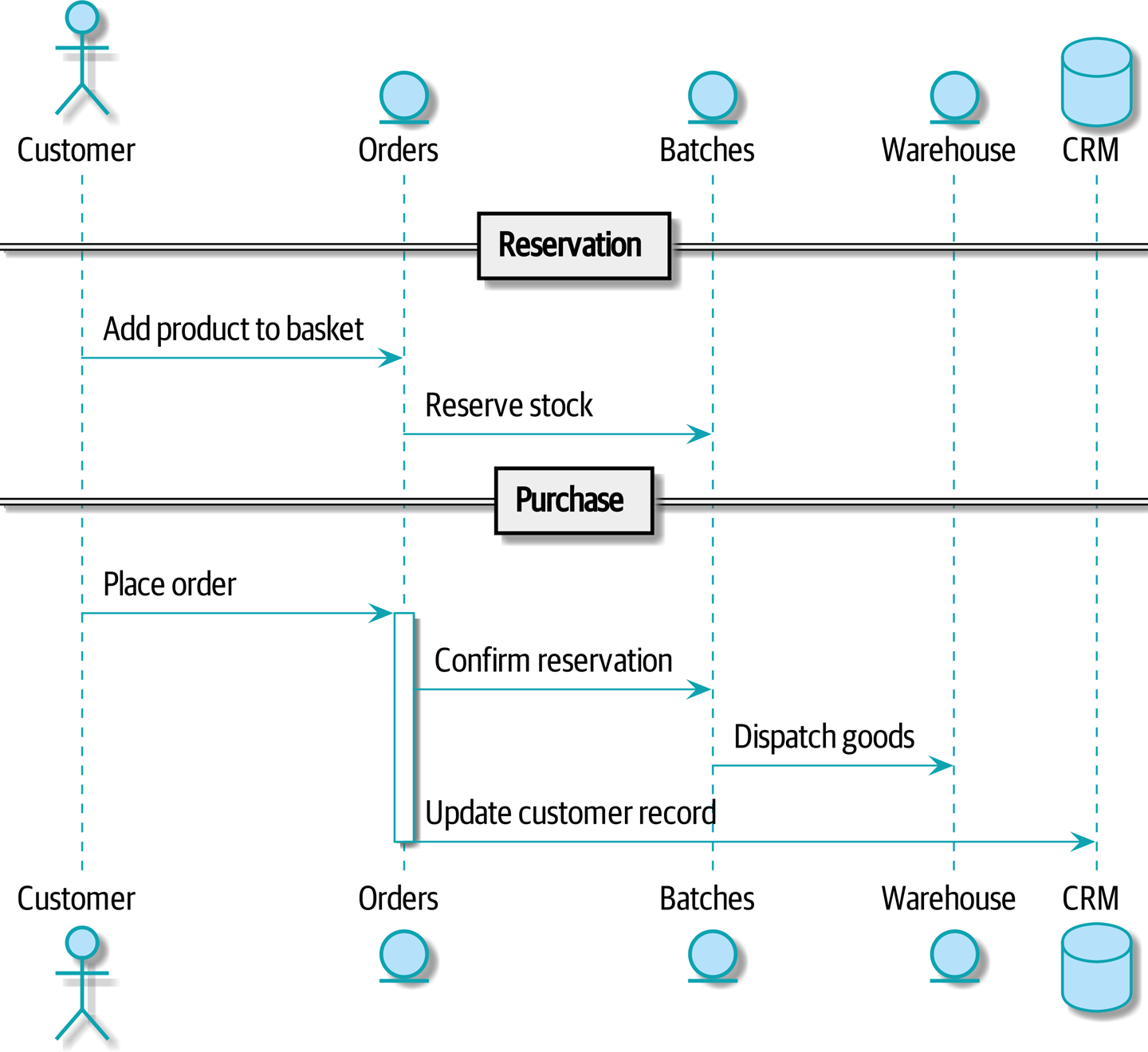
[plantuml, apwp_1103, config=plantuml.cfg] @startuml scale 4 actor Customer entity Orders entity Batches entity Warehouse database CRM == Reservation == Customer -> Orders: Add product to basket Orders -> Batches: Reserve stock == Purchase == Customer -> Orders: Place order activate Orders Orders -> Batches: Confirm reservation Batches -> Warehouse: Dispatch goods Orders -> CRM: Update customer record deactivate Orders @enduml
We can think of each of these steps as a command in our system: ReserveStock,
ConfirmReservation, DispatchGoods, MakeCustomerVIP, and so forth.
This style of architecture, where we create a microservice per database table and treat our HTTP APIs as CRUD interfaces to anemic models, is the most common initial way for people to approach service-oriented design.
This works fine for systems that are very simple, but it can quickly degrade into a distributed ball of mud.
To see why, let’s consider another case. Sometimes, when stock arrives at the warehouse, we discover that items have been water damaged during transit. We can’t sell water-damaged sofas, so we have to throw them away and request more stock from our partners. We also need to update our stock model, and that might mean we need to reallocate a customer’s order.
Where does this logic go?
Well, the Warehouse system knows that the stock has been damaged, so maybe it should own this process, as shown in Command flow 2.
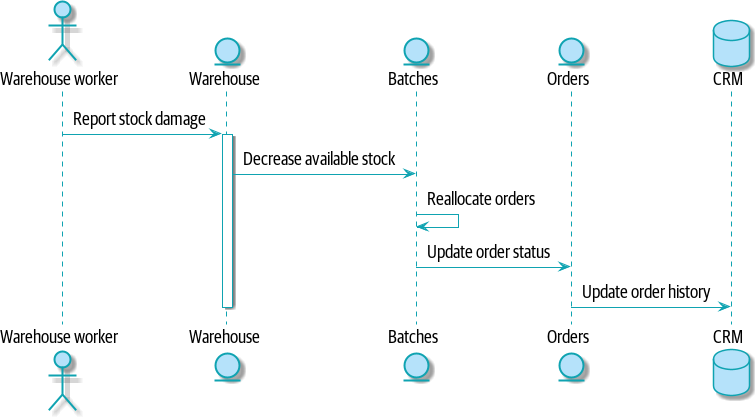
[plantuml, apwp_1104, config=plantuml.cfg] @startuml scale 4 actor w as "Warehouse worker" entity Warehouse entity Batches entity Orders database CRM w -> Warehouse: Report stock damage activate Warehouse Warehouse -> Batches: Decrease available stock Batches -> Batches: Reallocate orders Batches -> Orders: Update order status Orders -> CRM: Update order history deactivate Warehouse @enduml
This sort of works too, but now our dependency graph is a mess. To allocate stock, the Orders service drives the Batches system, which drives Warehouse; but in order to handle problems at the warehouse, our Warehouse system drives Batches, which drives Orders.
Multiply this by all the other workflows we need to provide, and you can see how services quickly get tangled up.
Error Handling in Distributed Systems
"Things break" is a universal law of software engineering. What happens in our
system when one of our requests fails? Let’s say that a network error happens
right after we take a user’s order for three MISBEGOTTEN-RUG, as shown in
Command flow with error.
We have two options here: we can place the order anyway and leave it unallocated, or we can refuse to take the order because the allocation can’t be guaranteed. The failure state of our batches service has bubbled up and is affecting the reliability of our order service.
When two things have to be changed together, we say that they are coupled. We can think of this failure cascade as a kind of temporal coupling: every part of the system has to work at the same time for any part of it to work. As the system gets bigger, there is an exponentially increasing probability that some part is degraded.
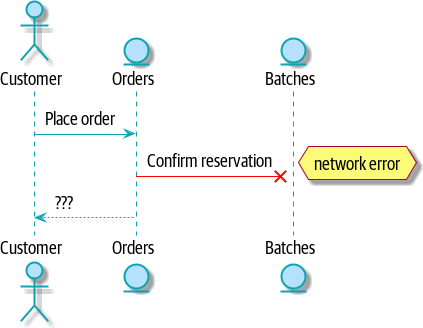
[plantuml, apwp_1105, config=plantuml.cfg] @startuml scale 4 actor Customer entity Orders entity Batches Customer -> Orders: Place order Orders -[#red]x Batches: Confirm reservation hnote right: network error Orders --> Customer: ??? @enduml
The Alternative: Temporal Decoupling Using Asynchronous Messaging
How do we get appropriate coupling? We’ve already seen part of the answer, which is that we should think in terms of verbs, not nouns. Our domain model is about modeling a business process. It’s not a static data model about a thing; it’s a model of a verb.
So instead of thinking about a system for orders and a system for batches, we think about a system for ordering and a system for allocating, and so on.
When we separate things this way, it’s a little easier to see which system should be responsible for what. When thinking about ordering, really we want to make sure that when we place an order, the order is placed. Everything else can happen later, so long as it happens.
|
Note
|
If this sounds familiar, it should! Segregating responsibilities is the same process we went through when designing our aggregates and commands. |
Like aggregates, microservices should be consistency boundaries. Between two services, we can accept eventual consistency, and that means we don’t need to rely on synchronous calls. Each service accepts commands from the outside world and raises events to record the result. Other services can listen to those events to trigger the next steps in the workflow.
To avoid the Distributed Ball of Mud antipattern, instead of temporally coupled HTTP
API calls, we want to use asynchronous messaging to integrate our systems. We
want our BatchQuantityChanged messages to come in as external messages from
upstream systems, and we want our system to publish Allocated events for
downstream systems to listen to.
Why is this better? First, because things can fail independently, it’s easier to handle degraded behavior: we can still take orders if the allocation system is having a bad day.
Second, we’re reducing the strength of coupling between our systems. If we need to change the order of operations or to introduce new steps in the process, we can do that locally.
Using a Redis Pub/Sub Channel for Integration
Let’s see how it will all work concretely. We’ll need some way of getting events out of one system and into another, like our message bus, but for services. This piece of infrastructure is often called a message broker. The role of a message broker is to take messages from publishers and deliver them to subscribers.
At MADE.com, we use Event Store; Kafka or RabbitMQ are valid alternatives. A lightweight solution based on Redis pub/sub channels can also work just fine, and because Redis is much more generally familiar to people, we thought we’d use it for this book.
|
Note
|
We’re glossing over the complexity involved in choosing the right messaging platform. Concerns like message ordering, failure handling, and idempotency all need to be thought through. For a few pointers, see [footguns]. |
Our new flow will look like Sequence diagram for reallocation flow:
Redis provides the BatchQuantityChanged event that kicks off the whole process, and our Allocated event is published back out to Redis again at the
end.
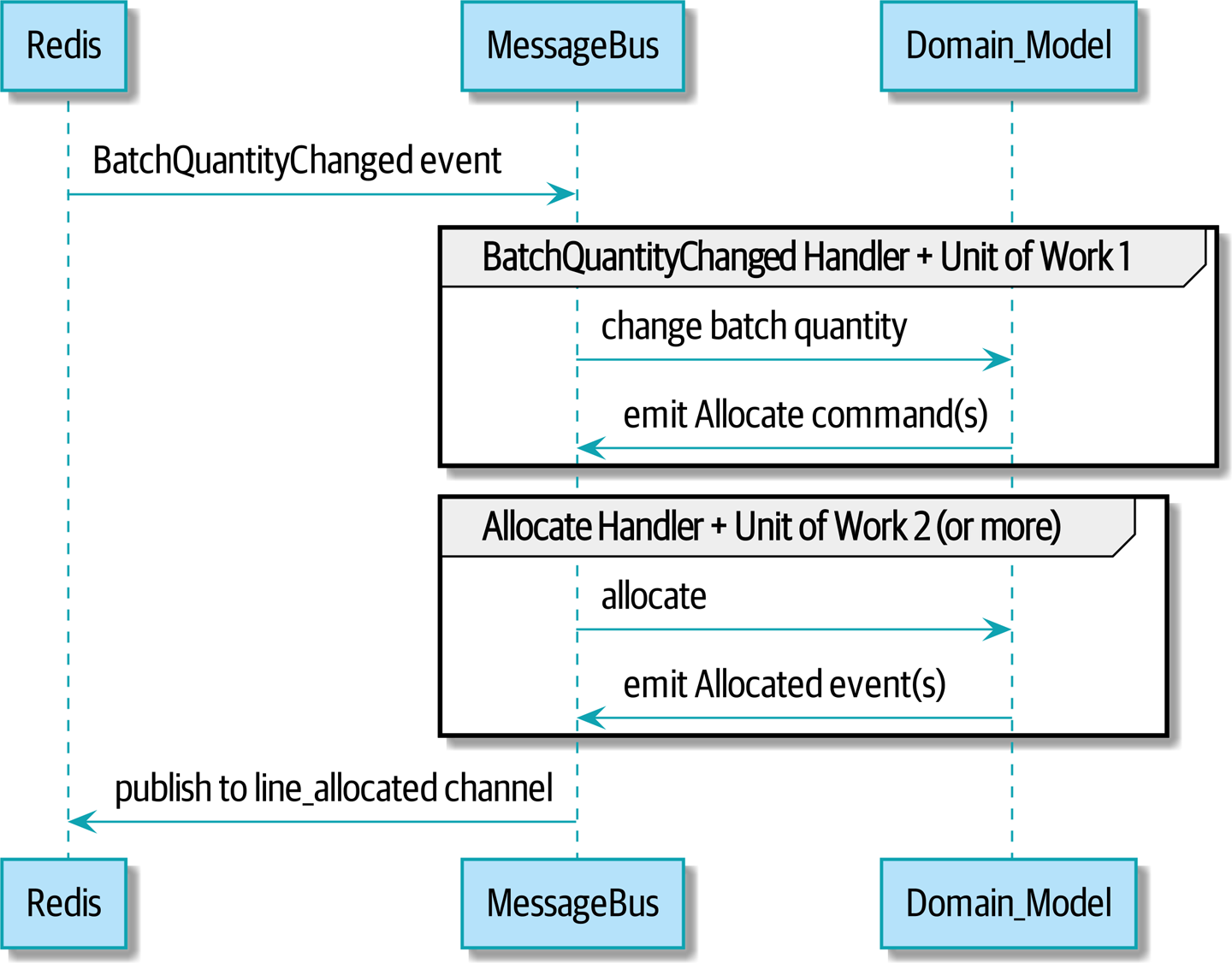
[plantuml, apwp_1106, config=plantuml.cfg]
@startuml
scale 4
Redis -> MessageBus : BatchQuantityChanged event
group BatchQuantityChanged Handler + Unit of Work 1
MessageBus -> Domain_Model : change batch quantity
Domain_Model -> MessageBus : emit Allocate command(s)
end
group Allocate Handler + Unit of Work 2 (or more)
MessageBus -> Domain_Model : allocate
Domain_Model -> MessageBus : emit Allocated event(s)
end
MessageBus -> Redis : publish to line_allocated channel
@enduml
Test-Driving It All Using an End-to-End Test
Here’s how we might start with an end-to-end test. We can use our existing API to create batches, and then we’ll test both inbound and outbound messages:
def test_change_batch_quantity_leading_to_reallocation():
# start with two batches and an order allocated to one of them #(1)
orderid, sku = random_orderid(), random_sku()
earlier_batch, later_batch = random_batchref("old"), random_batchref("newer")
api_client.post_to_add_batch(earlier_batch, sku, qty=10, eta="2011-01-01") #(2)
api_client.post_to_add_batch(later_batch, sku, qty=10, eta="2011-01-02")
response = api_client.post_to_allocate(orderid, sku, 10) #(2)
assert response.json()["batchref"] == earlier_batch
subscription = redis_client.subscribe_to("line_allocated") #(3)
# change quantity on allocated batch so it's less than our order #(1)
redis_client.publish_message( #(3)
"change_batch_quantity",
{"batchref": earlier_batch, "qty": 5},
)
# wait until we see a message saying the order has been reallocated #(1)
messages = []
for attempt in Retrying(stop=stop_after_delay(3), reraise=True): #(4)
with attempt:
message = subscription.get_message(timeout=1)
if message:
messages.append(message)
print(messages)
data = json.loads(messages[-1]["data"])
assert data["orderid"] == orderid
assert data["batchref"] == later_batch-
You can read the story of what’s going on in this test from the comments: we want to send an event into the system that causes an order line to be reallocated, and we see that reallocation come out as an event in Redis too.
-
api_clientis a little helper that we refactored out to share between our two test types; it wraps our calls torequests.post. -
redis_clientis another little test helper, the details of which don’t really matter; its job is to be able to send and receive messages from various Redis channels. We’ll use a channel calledchange_batch_quantityto send in our request to change the quantity for a batch, and we’ll listen to another channel calledline_allocatedto look out for the expected reallocation. -
Because of the asynchronous nature of the system under test, we need to use the
tenacitylibrary again to add a retry loop—first, because it may take some time for our newline_allocatedmessage to arrive, but also because it won’t be the only message on that channel.
Redis Is Another Thin Adapter Around Our Message Bus
Our Redis pub/sub listener (we call it an event consumer) is very much like Flask: it translates from the outside world to our events:
r = redis.Redis(**config.get_redis_host_and_port())
def main():
orm.start_mappers()
pubsub = r.pubsub(ignore_subscribe_messages=True)
pubsub.subscribe("change_batch_quantity") #(1)
for m in pubsub.listen():
handle_change_batch_quantity(m)
def handle_change_batch_quantity(m):
logging.debug("handling %s", m)
data = json.loads(m["data"]) #(2)
cmd = commands.ChangeBatchQuantity(ref=data["batchref"], qty=data["qty"]) #(2)
messagebus.handle(cmd, uow=unit_of_work.SqlAlchemyUnitOfWork())-
main()subscribes us to thechange_batch_quantitychannel on load. -
Our main job as an entrypoint to the system is to deserialize JSON, convert it to a
Command, and pass it to the service layer—much as the Flask adapter does.
We also build a new downstream adapter to do the opposite job—converting domain events to public events:
r = redis.Redis(**config.get_redis_host_and_port())
def publish(channel, event: events.Event): #(1)
logging.debug("publishing: channel=%s, event=%s", channel, event)
r.publish(channel, json.dumps(asdict(event)))-
We take a hardcoded channel here, but you could also store a mapping between event classes/names and the appropriate channel, allowing one or more message types to go to different channels.
Our New Outgoing Event
Here’s what the Allocated event will look like:
@dataclass
class Allocated(Event):
orderid: str
sku: str
qty: int
batchref: strIt captures everything we need to know about an allocation: the details of the order line, and which batch it was allocated to.
We add it into our model’s allocate() method (having added a test
first, naturally):
class Product:
...
def allocate(self, line: OrderLine) -> str:
...
batch.allocate(line)
self.version_number += 1
self.events.append(
events.Allocated(
orderid=line.orderid,
sku=line.sku,
qty=line.qty,
batchref=batch.reference,
)
)
return batch.reference
The handler for ChangeBatchQuantity already exists, so all we need to add
is a handler that publishes the outgoing event:
HANDLERS = {
events.Allocated: [handlers.publish_allocated_event],
events.OutOfStock: [handlers.send_out_of_stock_notification],
} # type: Dict[Type[events.Event], List[Callable]]Publishing the event uses our helper function from the Redis wrapper:
def publish_allocated_event(
event: events.Allocated,
uow: unit_of_work.AbstractUnitOfWork,
):
redis_eventpublisher.publish("line_allocated", event)Internal Versus External Events
It’s a good idea to keep the distinction between internal and external events clear. Some events may come from the outside, and some events may get upgraded and published externally, but not all of them will. This is particularly important if you get into event sourcing (very much a topic for another book, though).
|
Tip
|
Outbound events are one of the places it’s important to apply validation. See [appendix_validation] for some validation philosophy and examples. |
Wrap-Up
Events can come from the outside, but they can also be published
externally—our publish handler converts an event to a message on a Redis
channel. We use events to talk to the outside world. This kind of temporal
decoupling buys us a lot of flexibility in our application integrations, but
as always, it comes at a cost.
Event notification is nice because it implies a low level of coupling, and is pretty simple to set up. It can become problematic, however, if there really is a logical flow that runs over various event notifications...It can be hard to see such a flow as it's not explicit in any program text....This can make it hard to debug and modify.
Martin Fowler, "What do you mean by 'Event-Driven'"
Event-based microservices integration: the trade-offs shows some trade-offs to think about.
| Pros | Cons |
|---|---|
|
|
More generally, if you’re moving from a model of synchronous messaging to an async one, you also open up a whole host of problems having to do with message reliability and eventual consistency. Read on to [footguns].